|
|
0x01 HIDS的背景- u0 U/ I' T7 D; Z* r
. v8 ?7 r7 K- X8 d3 x
企业有各种安全防护手段,HIDS与网络流量监听一样, 是一种威胁检测的手段。HIDS(Host-based Intrusion Detection System)基于主机型入侵检测系统。与网络监听这种形式的主要区别是, HIDS的主要数据源来至于主机本身产生的各种审计信息。5 x2 F5 U0 Z+ p+ `
各公司在构架这样的系统时, 多多少少都会面临时相同的问题,其中有一个共通地方就是审计数据的存储方案如何建设,我们回顾了一下,讨论一下HIDS的数据处理流程,与相应存储方案的优劣。8 N: M4 E# P( y$ t
8 ]$ q$ p) _+ `9 F0x02 HIDS与网络监听
6 o( J4 i$ @* J8 \
/ x2 j/ r5 D& [) u通过在主机上安装一个审计数据收集的 agent代理程序,收集主机的相关信息。
% r# N l, n2 B5 AHIDS系统和其他的系统都很多的相似之处,也有着明显的区别。Agent安装收集数据,与网络分光流量监听对比最大的区别,在于要在机器上装Agent,这本身是成本(部署覆盖率,监控覆盖率),而网络分光只要将数据集中,就可以分析流量中的网络相关数据。% S; p$ X2 ]' t4 o
实际上Agent上收集的数据总量,几乎占到一半存储比例的还是网络数据, 比如:网络连接数据(异常链接、网络等待等)。
( S7 H s |' ^6 [. P: [, |某种程度HIDS与网络流量监听, 即互补又殊途同归。
! U6 I' H! ~9 M6 E2 J2 I% ^说到相同的地方, HIDS与其他的安全信息系统,有很多信息本身应该具备的组织部分,比如数据的存储,数据的分析,让安全运维人员与整个系统交互,进行安全策略的地方。% a$ n; |3 L( M- J; y
各大公司都有自己系统设计方案和建模方法, 他们用的审计数据源种类也许是相似的,大数据的存储方案也差不多, 建模的方法也是经典的建模方式,甚至有可能“攻击者”都是同一波人。
6 g% I6 Y! M' V+ q9 d基于类似的背景,才可能将整个方案通用化, 产品化。没有形成产品,也可以制定一个通用的模型框架。1 P: b$ r* g3 r0 t
0x03 数据处理流程. z5 A% S( Z7 w' s5 G9 V+ U7 P, P
% i" C2 O" r B2 N ~
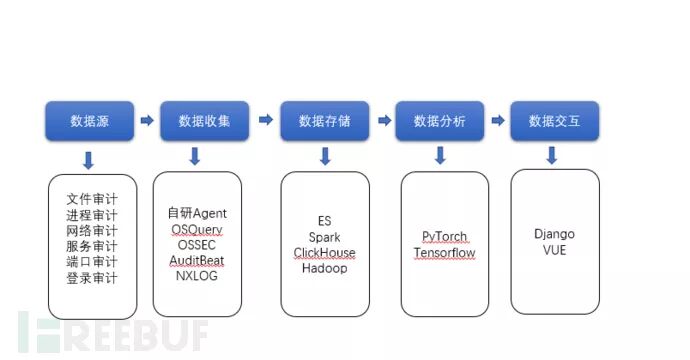
我们将整个系统分成几个模块,来看整个系统:1 C, V5 m0 Q+ j8 g/ \
数据源:主机服务器上有各种审计数据,这些审计的数据是整个系统的数据分析素材。账号信息、网络链接、登录信息、服务信息、处理器信息等。无论什么平台, 这些基本的审计信息几乎都是共有的。
* e- n# E+ C7 N5 F; l我们用OSQuery举例,用开源方案说明问题, 可以脱敏。' z$ R3 }& j9 b+ T1 D
比如,取得当前主机的端口监听:
4 H. s" I3 H. o, W; m
5 p3 X U* v$ [- . r& d8 V* y6 Z
osquery>select * from listening_ports pid | port| protocol|family | address 123| 808| 0 | 0 | 0.0.0.0市面上流通的入侵检测代理客户端(跨平台),很多是可以取得这些信息的。OSQuery是将主机各种类型的Audit信息,统一管理成了二维表(Virtual Table),提供了一个SQL查询引擎提供查询。
( v# {7 X8 f% \+ G' D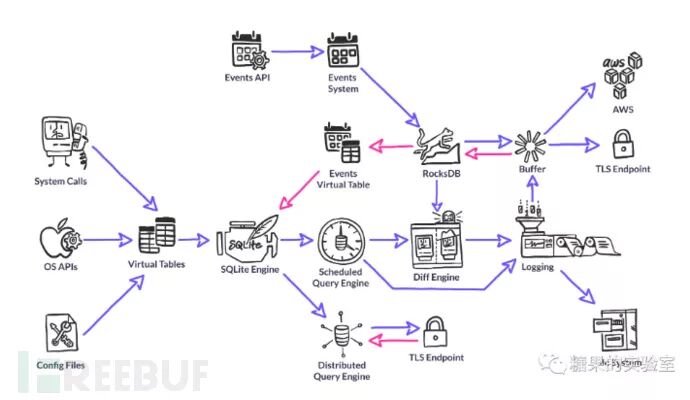
6 B& r; t8 k9 j, U( H5 LOSQuery架构图 ) a& k& m# a7 I
数据收集:面对各种主机审计数据源,系统必须要有一个数据收集能力。
8 {9 I% u+ o$ U) b) U/ @1 NHIDS一个很重要的组成部分是Agent, 不只是安全系统才有Agent,像Zabbix这种监控服务也同样用Agent。数据收集Agent方法有几种方法选择:1.自行研发。2.开源方案。 ) m d, k5 n' s0 W- A1 o
相同的目的:无论我们使用的开源方案,还是自研的Agent,目的都是一样的, 收集我们需要数据,服务器上的相关审计信息。只要能收集到我们想到的审计信息上这一点没有障碍,就达成目标。
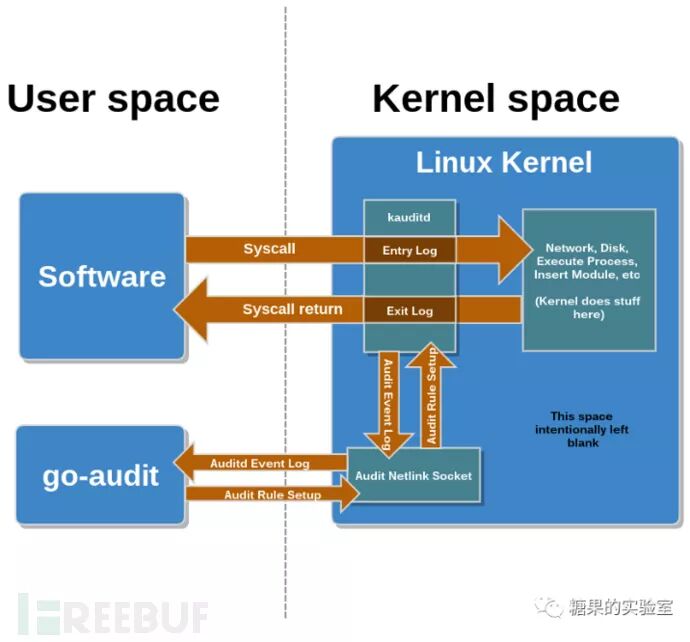
. s2 B, {. {! `0 R; ?5 y8 }无论我们是采用开源,还是自研的方案,系统底层的很多都是相通的。以Linux的系统为例子看下图。' z: S9 {; ]( [
 ' L9 R) k# w9 M; ~7 o ' L9 R) k# w9 M; ~7 o
OSQuery或是自研的Agent相当于图中的go-audit, 都是系统审计日志Client客户端调用者。使用pythonaudit和caudit底层调用的API都是系统API,区别是对各种平台的支持(跨平台),Agent的性能和健壮性。
( n5 P1 ]: j$ J3 u" c0 H8 j& p* |3 r[color=#777575 !important]自研Agent优点:对于自研agent来说,我们可以控制整个软件的逻辑, 尽情的加入我们想扩展的功能。
6 M* r. ~' o2 ]9 y- c9 d' a[color=#777575 !important]自研Agent劣势:需要大量的平台适配,保证测试的覆盖率,不能轻易挂,没有社区的服务支持。2 [; q1 b: _1 `
[color=#777575 !important]开源Agent优势:对于开源agent来说,开源Agent被行业充分的测试, 可以稳定的在企业各种已知的平台上,收集不同平台的数据,Linux、Windows、MAC。自研的方案各大厂都有自己的轮子。开源Agent方案:AuditBeat、OSQuery、NxLog等等,可以根据规模和平台的大小进行选择,各种入侵检测方案。
I5 `/ @2 R* n; j& C[color=#777575 !important]开源Agent劣势:需求的定制化和扩展性, 是否能适应企业审计需求,数据采集需求,后续是否会出现,软件停止维护等尴尬局面。
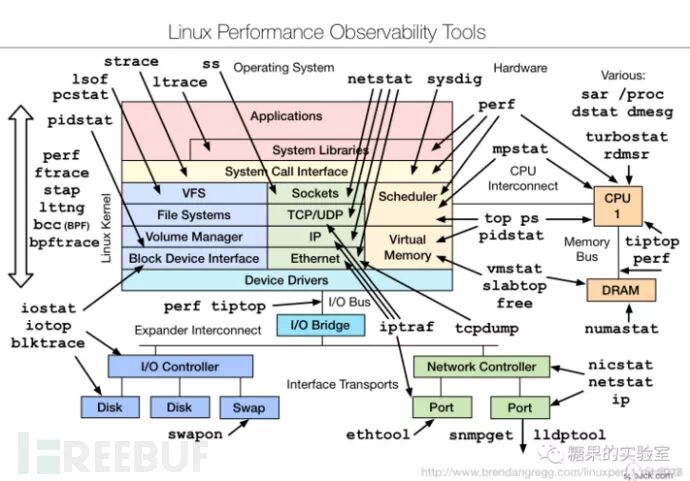
S( w* W9 e' q HIDS的Agent收集的数据,之前说过,占比最大的一块数据是网络相关数据(几乎总量50%),随着时间的推移,工具的进来,“Netstat”相关信息取得也发生了变化。" [- v [8 P+ ~/ R
 4 o q; Z6 Z( p ?% @2 q2 _# s 4 o q; Z6 Z( p ?% @2 q2 _# s
以上的图,可以看到工具是如何与操作系统交互取得底层数据,这种圆环套圆环,调用套调用的依赖关系, 如果都能简化成SQL这种DSL业务语言,简直就是太方便,把各种分类的审计信息全变成虚表,让安全人员专注于业务数据的审计和策略的构建迭代, 支持一下OSQuery这种SQL的设计方案。% b) V/ f7 V4 c- O
还有一个Agent结点集中管理后台问题。1 K% W8 h5 X+ E5 r4 t" W- r! B
OSQuery后台管理是有商业方案,但那不得花钱吗!所以有开源方案,如下:3 z7 Z/ m6 H. E2 X
[color=#777575 !important]https://github.com/shengnoah/osctrl/ T" ^# E4 M7 F2 N& I8 y1 B6 ^
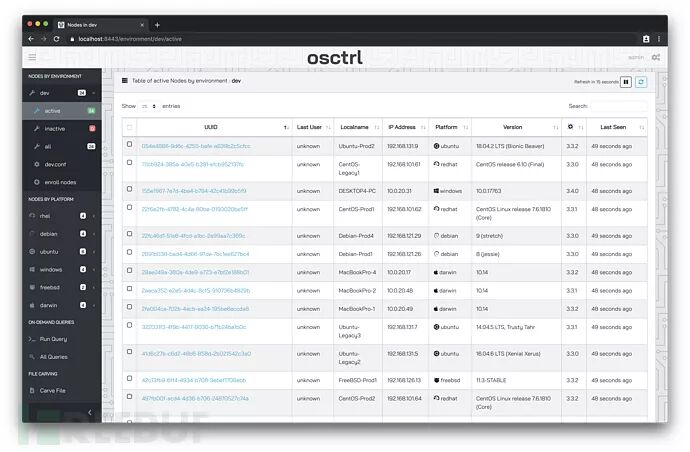
+ N# d3 @# [( h! y0 tosctrl是jmpsec推出的后台管理系统,Freebsd、Ubuntu、Debian等各种平台都支持。9 S0 y! Q# U; F+ o. r
如果您使用的本身是基于ELK的方案,没有Hive、Clickhouse、Spark这些什么事,还可以选择Auditbeat方案, 是Elastic同门产品,并且Elastic还直接支持了SIEM,至于适用不适用企业就具体分析。
- T1 ~) \7 H4 J% b9 N这样像SOC/SIEM类的产品, Elastic、Graylog、Splunk都有解决方案。前两者都有开源和企业版,后者是一定数据量之内处理不要钱, 过量就要钱,5 p, c4 J; y0 _* \2 y
如果企业的数据是,几十T,几百T的数据量,不花钱是不可能的。排除软件和运维成本,数据本身的生产,消费,存储的硬件成本就很明显的硬件成本。
8 [9 \' g) T2 z4 F) Y0x04 存储方案, I7 w) T/ r% W; ^% l" D0 ~( c
$ o3 } } @- Y* d- K5 X. h数据的存储:信息系统的一个核心是数据存储,数据库要保证基本的读写性能,扩展性,高可用性。0 `5 z0 [; ~! W1 i4 Y0 ?4 k) N% t
现在有成熟的大数据存储解决方案。
! d. k# ]9 |+ f9 e% j! o' _: R2 P x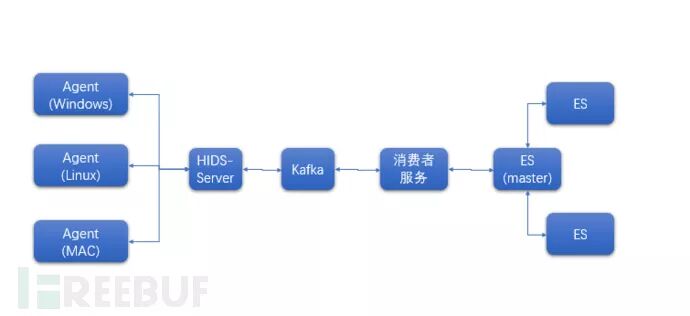
: U7 @. E; e& j6 C! E2 L4 qES集群核心存储方案(图2)
! _* e# z' v6 D3 S! l8 z0 ~ES:ES集群存储,最常见大数据方案之一,在实时计算场景, ES可以满足我们实时处理数据的要求。但同时ES的成本并不低。3 R3 x% w/ o. q* T- E2 l+ h& E* o. V
经过实践,ES集群为了稳定高可用,最少要用三台机器做结点,存两份数据的(1G的数据, 实际要用2G空间,有效使用空间低于2G),放到3台机器的不同分片, 这样才可能保证数据丢了可以找回来,要想达到数据访问的高性能,还需要配置高性的SSD磁盘。这都是钱。& g: v( c& T4 T8 t
只有ES不行,还需要配套的Buff队列Kafka前端机,前端消费机,只有带宽达到要求,缓存达到要求,才能保证存储服务的QPS。2万QPS至少12核左右的CPU,类推累计总消费量。, f; {% D$ V! f+ h1 i& X
ES优点:实时计算快,生态工具多。ES缺点:成本相对贵,需要配套的运维和调优。8 ` e, s& Q2 |/ w8 ?' d
需要专家配合才能让整个系统表现良好,默认的设置和优化的设置区别很大。! ]( R. I5 C. I! G% u: t- f
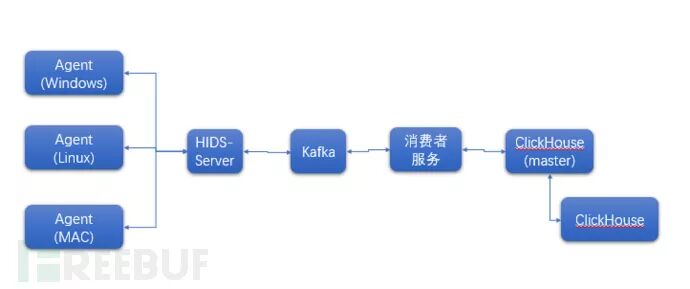 8 @' }* H& [0 c* j1 w8 G& } 8 @' }* H& [0 c* j1 w8 G& }
ClickHouse集群核心存储方案(图3)
: t7 ~$ P. i' U, ^ClickHouse:ClickHouse支持Mysql协议,存储空只需要原有数据的5分之1,1G的数据,200MB就可以保存(向高总致敬)。 并且检索的速度更快,相对使用机器更少。, s% D& {8 e+ Z% Q$ ?
OSQuery在收集取得审计数据时,使用的SQL结构化语言,ES也可以支持针对Index的Mysql查询,但从速度性能上看,ClickHouse最有优势(个人体验),并且ClickHouse本身就原生的支持SQL。0 Z" P5 ]7 P& W5 p, o. y
如果熟悉ClickHouse技术栈,Clickhouse也是一种主案,Clickhouse也同样需要前端机Kafka队列,也需要写Kafka数据,只是由原来的从Kafka写入ES,变成写入Clickhouse。3 \% X/ | P9 d2 E6 ?' Q
[color=#777575 !important]ClickHouse优点:存储空间小,速度性能快, 学习曲线不陡。ClickHouse缺点:生态没态ES多,需要自己实现一些服务工具链。
4 N1 w9 n( q" G9 W2 q 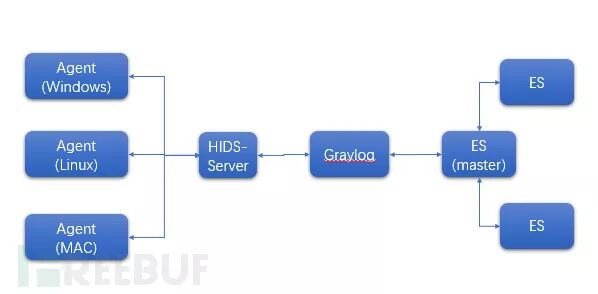 3 Y" v, T. h+ L5 P 3 Y" v, T. h+ L5 P
Graylog集群核心存储方案(图4)
# L+ n) g; y( y1 b, R7 VGraylog作为一个开源解决方案,本身就把自己定位成了SOC/SIM系统,新版的Graylog有审计Agent的对接,OSQuery方案,适应多种平台的审计数据采集,(Linux、Windwos、MAC),支持威胁情报管理。Graylog是基于Java技术栈的,整体打包了Kafka和消费程序,由Graylog组成的集群,整体解决了数据前端数据缓存到消费到ES上有服务流程, 还有Buff数据持久化等各种特性,这个之前糖果的实验室的公号和FB专栏发布的文章都有介绍,不太具体展开。Graylog在与ES配合的过程,需要优化配置才能有更好的性能表现, 默认的Graylog原生需要调配的,不然可能会达不到您的预期,在数据管理上造成困扰, 有时不是Graylog本身的问题,是配置方案选择的原因,需要专家积累和测试。) @' w9 x7 c. B
Hadopp集群核心存储方案
7 O% G+ _0 b- Y% ^Hadoop:Hadoop要求存储空间是原文本的3倍, 对于中小规模的系统,几千台的服务器。如果用10T的数据存储,整个的实际的空间就要30T,而实际实时性上,不一定比ES和Clickhouse快。& e3 H. E+ V4 g/ t
数据存储的占比,HIDS几乎50%数据存储空间,都是在存储网络相关数据,其他类别数据5倍,甚至是50倍。HIDS系统的大头数据,是主机网络相关数据。
( `" G: ?& T' B! d[color=#777575 !important]优点:功能强大,生态强大。缺点:基础设施构建成本高,需要专业团队运维,不是一天两天玩的转。
: ]% V( O" r3 V% p( c: l4 T 除了以上的方案还有Spark等其它的方案,成熟的技术在公司内部本身都有(ES、Clickhouse、Spark、Hadoop), 最后我们根据过去的经验和当前形势综合考虑,最后选择ES方案。8 h% t+ T x( C8 d6 O& c
数据分析:随着积累沉淀的数据变多,存储多不意味着系统产出的收益多。基于规则模式的古典分析模式,在超大规模的数据存储过程中,存在视角上的盲点,和人力运维的巨大成本。威胁变化多样,我们需要的不只是指那打那规则策略系统,需要系统有举一反三的能力, 有联想威胁能力。基于AI、基于NLP、基于规则、基于语议分析都可以数据收集后,对原始审计数据中的威胁进行发掘。HIDS收集的数据有时可对应的算法,是否可能被有效的挖掘出数据, 不是一概而论,因为太多数据类型的审计日志, 需要挖掘建模方法,有时模型和威胁元数据是同样重要的。' ?: x/ P% g* `+ X2 O
数据交互:整个HIDS最主要的操作者还是安全运维人员,让HIDS可以让安装运维人员配置策略,像无数安全分析系统一样,将威胁信息统计汇总。对于闭环的系统来说, 不需要过多的确认, 直接将威胁信息推给安全人员,直接响应是最理想的,这样运维人员,基本上不上后台系统,等着系统推送威胁给我们就好的理想状态。
1 K+ Y- N. g4 d5 X* ?, y. ]2 q" n[color=#777575 !important]“威胁告警是观点,不是结论。”一个百发百中的威胁发现系统,是需要完备的数据证据链路,提供支持,HIDS也只是数据链路上的一条。
- l" L2 y/ N2 x& E 因为证据链不全,才有了后期再分析判断的中间过程, 如果证据事实确凿,行动就行了,关键是证据链不全,最后还是需要先分析, 再决策,然后才能不瞎行动。+ @* R" s; E4 ?* h
0x05 总结 y, r: A* I5 ~3 J7 n% S
: j, I5 m$ F' ?( F& C
经过几种方案的对比, 最后我们在ES、Clickhouse、Hadoop之间选择了ES集群为中心的数据存储方案,只是在目前这个阶段,基于当前规模和成本的计算,综合数据威胁分析实时性考虑,我们选择了一个相对比较适合我们场景的方案,不同企业具体情况具体分析, 但是选案的原理和资源计算方法是可以参考的。
( f8 P4 y$ g c+ Y1 N9 q对于那些,没有成本预算自研HIDS中小型公司,可以选择多种开源方案解决OSQuery、AuditBeat、OSSEC总有一款适合您。' c% t2 n: F; h6 ~; l
参考:5 n1 D5 @/ z. X$ m
1 a7 J7 U3 C! e; t+ W2 Y* L* tSyscall Auditing at Scale
* V% M7 Z, A$ _: Z" `[color=#777575 !important]https://slack.engineering/syscall-auditing-at-scale-e6a3ca8ac1b8
' v' @6 o# [# m* P# k. h8 A3 M, ? *本文原创作者:糖果L5Q,本文属于FreeBuf原创奖励计划,未经许可禁止转载 . i9 q( O# p. l D" }" y+ d7 W
8 b8 B& W% c \: `精彩推荐
* G+ A+ C0 K1 ^* u- Q % n* i6 G Y( Y% Y % n* i6 G Y( Y% Y
 ; C$ O7 S0 [+ t2 s( n; I ; C$ O7 S0 [+ t2 s( n; I
  : k# x V5 f' ]' M; G1 Y3 f" Q u : k# x V5 f' ]' M; G1 Y3 f" Q u
) q0 I8 ~7 [- j2 N) i2 ^5 K* o
# @1 [( u% R, d4 }. ]3 S来源:http://mp.weixin.qq.com/s?src=11×tamp=1577106005&ver=2052&signature=TOp2rWi5tKlIEFwUHz3u7DT8-J9KpsMHyuuWNIrRy21lhopqTD0ukz7SndieKHTIernqgs3kZKI6rwJOD58oI59HVhFJ3n*jFdBv00VgP9CBeoI1-d9VRMCWrgAFjhsb&new=1
! k. K+ v! s' W$ N5 ^' G2 x4 o免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册

×
|
 |手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图
|手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图

 发表于 2019-12-23 21:14:37
发表于 2019-12-23 21:14:37
