& O0 V% v( F3 u6 H; v+ m- \市场被催熟,巨头进场收割。
- Q$ z& E4 M6 |边缘智能,人工智能的最后一公里,很长一段时间里被创业者视为得以绕开巨头打压的蓝海市场,在今年开始有了微妙的变化。* z3 o _9 s6 `
2 e. r9 W3 m$ x2 F% R
7 n# Q) Y R1 T* m+ r! ?$ I0 Z撰文 | 四月、力琴感谢机器之心海外记者袁渊提供相关资料
( s3 J+ [* D* p; W! c11 月 13 日机器之心消息,北京时间今日凌晨 2 点,英特尔在旧金山举行 2019 人工智能峰会,推出从边缘到云端到全新 AI 芯片,包括下一代英特尔 Movidius Myriad 视觉处理单元 (VPU),用于边缘媒体、计算机视觉和推理应用,以及难产三年终于落地的 Nervana 系列,面向训练 (NNP-T1000) 和面向推理 (NNP-I1000) 的 Nervana 神经网络处理器 (NNP)。0 l* X/ f: ]. P. h ? q
三条 AI 芯片产品线的发布,标志着英特尔人工智能业务获得实质进展。- a8 }# _' K+ P

v% L( [) \ V; h在最近的财报电话会议上,英特尔乐观地预测,2019 年人工智能的年收入达到 35 亿美元,高于 2017 年的 10 亿美元,完成 2022 年 100 亿美元目标的三分之一以上。
, } F$ U1 q/ o) h英特尔透露,在无人机、相机、机器人和自动驾驶汽车等设备的边缘计算收入同比增长了 20%。+ a K" Y* N% q6 {! D( P- F
「这一数字将逐年增长,基于我们的广度与深度,已经从数据中心走到边缘。」英特尔公司副总裁兼 AI 产品事业部总经理 Naveen Rao 表示。( n. F8 V* s* i! G# B
1
; @$ j! n: x `- ?! \& Q2 `边缘端性能十倍提升
% ?' E' H D' d2 E9 V1 j) d0 \英特尔详细介绍了代号为 Keem Bay 的下一代 Movidius Myriad 视觉处理单元(VPU),该单元针对边缘推理任务进行了优化。7 C |2 x0 M9 h9 k
* X0 `- v: l* s( P英特尔物联网副总裁乔纳森·巴伦(Jonathan Ballon)表示,该芯片拥有一种新的片上存储器架构,具有 64 位存储器带宽,性能是上一代产品的约 10 倍。7 Z( h" Q1 {; t) |6 N7 m
 机器之心现场实拍 机器之心现场实拍巴伦称:「它将以比同类产品低一倍的性能,几分之一的尺寸和成本来提供优于 GPU 的性能。」
8 P9 v+ L7 t9 _% ~Keem Bay 中封装了用于计算机视觉的专用芯片和 12 个可加快运行速度的专用(SHAVE)处理器内核,可使用 Myriad Development Kit(MDK)进行编程,从而兼容更多 AI 算法。
1 Y& x. ?! [1 Q3 w英特尔表示,Keem Bay 的功耗是 Nvidia 的 Jetson TX2 的四分之一,比华为昇腾(Ascend)310 计算速度快 1.25 倍。在特定情况下,能效比竞争对手的处理器高六倍,每秒提供的 TOPS 推理量是 Nvidia 的 Xavier 的四倍。
# R9 v" n( l2 d4 i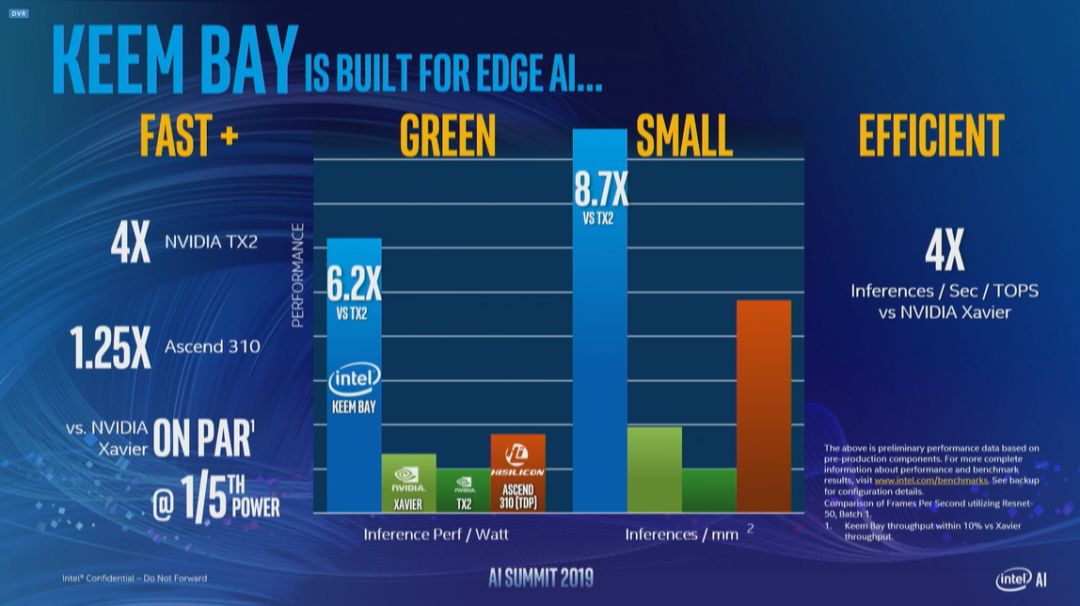
* J# s, e" e* A) z6 e该款芯片将在 2020 年上半年推出,包括 PCI Express 和 M.2 等形式。+ o5 Y( l! [. x: j. k2 t3 N
早在 2016 年 9 月,英特尔就收购总部位于圣马特奥的 AI 初创团队 Movidius,设计用于计算机视觉的专用低功耗处理器芯片,为其终端算力市场步下重要一子。
* b- X1 L% i$ ]! e/ [" Y, K, N2017 年,英特尔推出 Myriad 2,被 Google 的 Clips 相机,大疆的 Phantom 4 无人机,和国内安防市场的高端摄像头所采用。/ A2 f9 V+ V4 p. M: Z4 `
随后推出的 Myriad X 具有改进的成像和视觉引擎,包括附加的可编程 SHAVE 内核和升级的视觉加速器,以及支持多达 8 个高清传感器的本地 4K 图像处理器管线。6 N4 e2 g' J; C; w* O5 K
参考英伟达在软件生态的深厚基础而能厚积薄发,这次巴伦也着重强调了,英特尔在软件与开发工具方面的努力,使用英特尔OpenVINO 工具包的客户可以获得大约 50%的额外性能。# `3 P# i; P/ N; s; E3 D1 t; m3 N
基于 OpenVINO 工具包,Edge AI DevCloud 能够对无人机和摄像头等边缘设备进行 AI 原型和测试,开发人员可以使用现有工具和框架免费测试和优化 OpenVINO 中用于 Intel 硬件(例如 CPU 或 FPGA)的模型。; @+ ~1 i- w% a3 x
随着 Edge AI DevCloud 的发布,客户现在能够使用在夏季推出的 Deep Learning Workbench 工具进行建模和仿真,然后将其免费部署在开发云中的各种不同硬件配置上。# k. D7 j! \7 c4 `
Ballon 在与 VentureBeat 的一次对话中称,OpenVINO 是英特尔历史上增长最快的工具。
" h& [" a! n% E! Y2 c3 w: u' p2018 年 5 月,英特尔首次向开发人员和制造商提供 OpenVINO 或开放式视觉推理和神经网络优化,以使用英特尔硬件进行深度学习推理。( _7 ?6 E+ p5 R: H
OpenVINO 支持从 CPU,GPU 和 FPGA 到 Intel Movidius 神经计算棒的一系列机器学习加速器。该工具包于今年早些时候进行了更新,以扩展到计算机视觉应用之外,并支持语音和 NLP 模型。
& P. L/ u7 n( u- G0 g英特尔今天还与 Udacity 一起推出用于物联网纳米级程序的 Edge AI。据悉,正在创建的数据中有 70%位于边缘,只有一半将进入公共云,其余的将在边缘存储和处理。
" E2 d' Z' K1 L: T0 g2! w7 g5 C; [; X% I1 f3 ` P
云端AI芯片终商用
8 y/ V6 o0 k6 ]# K在终端之外,英特尔当然没忘最核心的数据中心市场,Nervana 产品线难产三年终于落地。
3 H# Y% K/ R3 x, Z
& B- V. v- d7 H- ~) V, G英特尔推出面向 AI 推理和 AI 训练领域的两个系列产品,分别是神经网络训练处理器(Intel Nervana NNP-T)和神经网络推理处理器(Intel Nervana NNP-I),作为英特尔为云端和数据中心客户提供的首个针对复杂深度学习的专用 ASIC 芯片。 Z. Q6 y! n0 M/ b w1 [4 g/ {
 - q- t3 V$ g3 x# \% U/ n: n3 y' u- ] - q- t3 V$ g3 x# \% U/ n: n3 y' u- ]
训练芯片 NNP-T 采用台积电 16nm 制程工艺,拥有 270 亿个晶体管,硅片总面积达 680 平方毫米,支持所有主流深度学习框架。& @% L+ q- @# V' _2 I
 机器之心现场实拍推理芯片 NNP-I 基于英特尔 10nm Ice Lake 处理器架构,在 ResNet50 上的效率可达 4.8 TOPs/W,功率范围为 10W 到 50W 之间,同样支持所有的主流深度学习框架。早在 2016 年,英特尔就提出启动 Nervana 神经网络处理器的项目研发,直到今年才正式揭晓,并宣告正式投入生产,并实现商用。$ ]( o$ r) w3 R+ o5 W0 Z% h' [5 D 机器之心现场实拍推理芯片 NNP-I 基于英特尔 10nm Ice Lake 处理器架构,在 ResNet50 上的效率可达 4.8 TOPs/W,功率范围为 10W 到 50W 之间,同样支持所有的主流深度学习框架。早在 2016 年,英特尔就提出启动 Nervana 神经网络处理器的项目研发,直到今年才正式揭晓,并宣告正式投入生产,并实现商用。$ ]( o$ r) w3 R+ o5 W0 Z% h' [5 D
值得注意的是,这两款产品面向百度、 Facebook 等前沿人工智能客户,并针对这些企业的 AI 处理需求进行定制开发。# E8 y k% n$ c
谈到英特尔Nervana的独特性和优势时,英特尔公司人工智能产品事业部副总裁、推理产品事业部总经理Gadi Singer向机器之心表示,主要集中在功效、功能、规模化三个方面。9 c4 I4 Z( O# {6 I/ K( x, X. _
& e7 D6 K% I6 J" u* e# F( h! f# N
- 1)在功效方面,Nervana提供了非常节能的构建模块(building blocks),大概能提供10到15瓦的解决方案,可以单独使用,也可以基于需求将多个模块集成。因此无论大小,都能满足用户在任何级别上构建解决方案。2 J) k# U1 b! f% H' D
- 2)多功能性。不同于市面上的图像或语音单功能处理器,Nervana的立项之初就是必须支持多种用途。通过构建一组深度学习的功能,可以被应用多个不同类型的机器学习任务中。
* y& I# Y, c- u! A因为在大型云服务应用某些内容时,需要以多种形式使用它,因此需要在广泛的范围内提供良好的解决方案。
) M5 _2 [! p" ?4 u! s深度学习变化得如此之快,AI从某个研究实验室到或公司开始注意到开发再到部署可能只需要不到一年的时间,就好比去年BERT出来时, 三个月内大家对它进行了广泛的试验,一年之内对其进行了非常大规模的部署。/ D9 l- e# @ ]- u; }
在瞬息万变的环境下,研发出一个能随时‘准备就绪’的通用解决方案,我们才可以解决甚至还没有被广泛关注的新问题。因此,我们的架构是使用构建模块不断进行重组。, N' l E5 |; G9 K8 z& i2 Q/ B
- 3)最后是规模化,比起硬件方面,更多组员主攻的是软件这个部分。软件对整个解决方案的优化非常关键,比如软件能了解在不同的内存位置以及使用这些功能分别需要的时长,软件能每个数据模块的使用频率并把它们放置在正确的位置上,让你可以最高效地使用推理计算引擎。
9 y, r* p3 j" D8 k% R% m, s0 }' HNervana架构与某些单一用途的同类产品不同,使用带有接口通道的API分层构建它。最底层的API直接与硬件打交道,然后中间会有一些类似于图谱节点的API,像是深度学习图谱中的高级计算单元,然后最高层的软件层将它们映射到用户所需要的任何应用程序接口中。
1 G9 D, Q& f! P( M- n " c8 s# B- X# `+ W
3
! d; [+ K% D/ B/ |巨头掘力终端
' u- M: x8 f" [9 ^4 [ `不止于英特尔,细心观察就会发现,今年巨头发力终端和边缘端的算力市场比以往声量更大。这在某种意义上也标志着终端 AI 芯片市场的成熟,巨头开始收割。
! H/ j4 Q+ E g0 Q* i3 T! L% \# ?4 l1、英伟达5 m# L Q. w/ Y
Jetson 是英伟达在面向嵌入式市场的产品线,正是对标英特尔 Movidius。区别于其他边缘 SoC 的特点,Jetson 家族强调并行运行多个神经网络。
6 j K! Z- y! `: ^, ~" t2 Z9 T6 n截至目前,Jetson 已发布四个系列,包括 Jetson TX1、Jetson TX2、Jetson Nano、Jetson Xavier NX,主要部署在边缘与终端应用上,适用于机器人、无人机和智能摄像头等应用。
1 S0 F# Z& O3 W" Z k- G( X4 \2 { ) s; |+ A3 p3 i' }% h ) s; |+ A3 p3 i' }% h
2017 年,英伟达推出首款采用 Pascal GPU 架构(16 nm 工艺)的芯片 Jetson TX2,大小相当于一张信用卡。官方给出的数据显示,TX2 可在 MAX Q、MAX P 两种状态下运行,功耗在 7.5W-5W。
, w: Y; k8 t4 G4 P. v9 T2018 年,英伟达发布 Jetson 系统级模块——AGX Xavier,可提供工作站级别的任务执行性能。AGX Xavier 有 10W/15W/30W 三种选择,神经网络运算输出为 32TOPS,可应付多达四路的 HEFC 4K 、60fps 视频流。7 ]' [/ @( o* d" f) k
而就在上周,英伟达进一步推出 Jetson 的最新成员 Jetson Xavier NX,号称「全球最小边缘超算」。+ N) `! f8 ` q
 + p, S# E) z6 l3 `& c6 ~5 s + p, S# E) z6 l3 `& c6 ~5 s
可提供高达 14 TOPS(功耗为 10W 时)或 21 TOPS(功耗为 15W 时)的性能,能够并行运行多个神经网络,并在与 Nano 同样尺寸(70x45mm)的小巧外形中同时处理来自多个高分辨率传感器的数据。
4 k. m! I9 z' ^7 g7 t1 F7 oXavier NX 将于明年 3 月开始发售,价格 399 美元。" V- Y+ I! X F* V1 A$ u% f
与此同时,英伟达为 Jetson 配置了一套开放式平台和完整的 AI 软件堆栈 JetPack SDK,可以运行复杂的 AI 网络,并用于深度学习的加速库以及计算机视觉、计算机图形、多媒体等。% F. i, |! H5 u$ j2 `& f+ h
2、谷歌0 m/ `* @; h3 e, D0 c+ K
今年年早些时候,谷歌推出名为 Coral 的本地终端 AI 平台,是 TPU 的边缘芯片版本,强调以低功耗水平提高出色的 ML 推理性能。能够以良好的功率表现执行 MobileNet v2 等最先进的移动视觉模型,且 fps 可达 100 以上。
. A8 _' a2 ]) R8 P Coral USB 加速棒(图左)与第一代英特尔神经计算棒(图右)。基于 Corel 平台,谷歌发布了五款设备,分别是单板计算机「Coral Dev Board」、支持 Raspberry Pi 或 Debian Linux 计算机的 USB 加速器、对应 Dev Board 的 500 万像素镜头模块、 Dev Board 的系统模块(SoM),和轻易将机器学习加速器 Edge TPU 与现有计算机系统整合的 PCI-E 加速器。3、华为 Coral USB 加速棒(图左)与第一代英特尔神经计算棒(图右)。基于 Corel 平台,谷歌发布了五款设备,分别是单板计算机「Coral Dev Board」、支持 Raspberry Pi 或 Debian Linux 计算机的 USB 加速器、对应 Dev Board 的 500 万像素镜头模块、 Dev Board 的系统模块(SoM),和轻易将机器学习加速器 Edge TPU 与现有计算机系统整合的 PCI-E 加速器。3、华为
9 c+ Z" o: p3 Y; m2 s1 x. i看国内市场,当属华为作为风向标。) X& Q$ B5 ?- ]' r7 [
去年,华为发布全面自研芯片信号,昇腾则是其推出的首款面向边缘计算品牌,采用华为自有的达芬奇架构(12nm 工艺),使用华为自有的高效灵活 CISC 指令集。& H8 V9 Z1 b5 f! ]# h: ~
昇腾系列除了瞄准机器人、智能制造等终端智能产品,同时也是华为在安防智能摄像头和边缘计算的重要布局。) y: `/ e" O# l' M
昇腾 310 最大功耗为 8W,半精度(FP16)运算能力 8TFLOPS,整数精度(INT8)16TOPS,支持 16 通道全高清视频解码(H.264/265)。在今年上半年正式推出。3 t" J! S+ }1 g
4* r: K4 p: |; r
AI芯片创业压力加剧
" k' D! n5 F1 X j: V4 a2 H很长一段时间里,由于云端 AI 芯片市场被集中垄断,同时更加依赖生态,导致大部分 AI 芯片的初创公司都将目标瞄准在边缘和终端市场,以各种 AI 加速器或 SoC 芯片的形式走向市场。0 x3 ^. b3 [; v4 r3 X
+ [" X, S. K2 E; l
通过独特的架构设计以及领先的性能指标的芯片,以求在分散而潜力巨大的物联网市场分得一杯羹。% `; F: O9 ~2 F3 J$ [2 @3 Z9 \
如今,英特尔 Myriad Keem Bay、英伟达 Jetson Xavier NX 的推出不仅标志着巨头边缘端 AI 芯片布局的完善和实力的进一步增强,同时也是边缘端芯片市场竞争更加激烈的强烈信号。
2 l$ d6 \1 Y9 f. s0 P; P$ \巨头的 AI 芯片触角蔓延至边缘端,将让 AI 芯片初创公司面临着更加严峻的生存挑战。
4 h2 d- Y2 }3 a4 w; P: _" H机器之心Pro
' i% F8 g6 j2 N" a, F追动态 | 查数据 | 找资源 | 读报告 | 做调研 + P+ a! I0 Y2 ~8 P
, f k4 s% \3 _- u! P3 g$ ~0 k- i6 {. U
机器之心Pro 是基于「机器之心团队构建的百万级规模人工智能知识图谱及结构化数据库」搭建的人工智能领域专业信息平台。( W- m6 Y9 m- L0 A3 B
0 |# i* E8 F# S: F" q* |+ k/ u$ U3 m" x& y9 \6 I5 g4 y& y" ^
目前已上线五个模块:dashboard、新闻数据库、行业数据库、人工智能知识库和深度精选,覆盖 38 个技术领域及 55 个智能应用领域。
K9 E: x" y- m# z- o4 k
, y0 \5 ~: b! j- A, k
0 p( m/ e0 V$ ~/ L/ [5 Q+ l
$ u8 X8 q3 E# m9 L点击图片,查看官方使用手册. A2 }; { `# U) Q
1 y7 O( o, p2 Z+ D, ~/ k
$ f. m. h' H0 ~3 O1 E
2 G% L- B% O9 `8 H9 K/ x" G' D2 N; l2 ^$ a. Y* o- @2 d1 |
/ k- O# D: s: ]( `6 |0 m
pro.jiqizhixin.com3 K) b4 k) ?1 _- `# c2 [
盯动态、找资源、做调研; ~0 N( s8 F, r# F$ b; y, r b
1 ?+ d( M! {* b+ D f
. s. _. h1 I8 Q! D* J
! b! m6 S5 N* a, S% W来源:http://mp.weixin.qq.com/s?src=11×tamp=1573628405&ver=1971&signature=T5-sAwq-3m5Q2XlXSyEJnWUzh*XzLRqDFNvi*WAAS8uu4I4H4Re6QNqwZbiN4Ovbj*Y3-E5GkoZ3ZrDQ3TQtQV6Be2aXF9hTw59p6X72-r5hzKx5ru-uIEq9FLCRlQ4t&new=1& ?! x3 R& m( N6 c( l" j+ F
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
 |手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图
|手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图

 发表于 2019-11-13 15:35:28
发表于 2019-11-13 15:35:28

