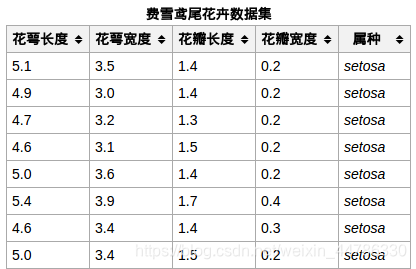
目录一、iris数据集简介iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson`s Iris data set。iris包罗150个样本,对应数据集的每行数据。 每行数据包罗每个样本的四个特性和样本的类别信息,所以iris数据集是一个150行5列的二维表。 通俗地说,iris数据集是用来给花做分类的数据集,每个样本包罗了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特性(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特性来判断样本属于山鸢尾(setosa)、变色鸢尾(versicolor)、维吉尼亚鸢尾(virginica)这三个名词都是花的品种。iris的每个样本都包罗了品种信息,即目的属性(第5列,也叫target或label) 如图所示部门数据:
iris在呆板学习中的应用:
二、根本数据操作和模型练习1.加载iris数据集 [code]# iris数据集加载 from sklearn import datasets iris = datasets.load_iris()[/code]2.展示所有数据 [code]#展示数据 print(iris.data )[/code]3.展示每列的属性名 [code]print(iris.feature_names)[/code]4.展示输出目的效果以及效果的寄义 [code]print(iris.target) print(iris.target_names)[/code]5.查看输入和输出数据类型 [code]print(type(iris.data)) print(type(iris.target))[/code]6.确认行列维度 [code]print(iris.data.shape) print(iris.target.shape)[/code]7.给x,y赋值 [code]X =iris.data Y = iris.target[/code]8.利用knn模型举行猜测效果 [code]from sklearn.neighbors import KNeighborsClassifier #创建实例,假设k值为1 knn = KNeighborsClassifier(n_neighbors=1) #练习数据集模型 knn.fit(x,y)[/code]9.给定特性的值猜测花的品种 [code]#猜测某种花的品种 knn.predict([[1,2,3,4]])[/code]
得到数组的数据 “2” ,它代表的是花萼长度为1、花萼宽度为2、花瓣长度为3、花瓣宽度为4的鸢尾花卉猜测效果的品种是第三种:维吉尼亚鸢尾(virginica) [code]#多种花的猜测 x_test = [[1,2,3,4],[2,4,1,2]] knn.predict(x_test) `[/code]
得到数组的数据 “2” 和 “0”,它代表的是
总结以上为个人履历,盼望能给大家一个参考,也盼望大家多多支持脚本之家。 来源:https://www.jb51.net/python/32892820i.htm 免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
 /6
/6 
 |手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图
|手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图
GMT+8, 2025-9-18 19:17 , Processed in 0.067156 second(s), 19 queries .
Powered by Mxzdjyxk! X3.5
© 2001-2025 Discuz! Team.