|
机器之心报道 % U; V6 w% X5 o! n' O
机器之心编辑部「DeepNumPy 可以写深度模型,且与经典 NumPy 100% 兼容」,AWS 副总裁 Smola 说,「深度图学习本领强大,Transformer 也可以分解为图」。「Julia 内建可微分编程,定义任何函数,他就会自动算出值以及梯度!」,Julia 创始人 Viral 说。这就是 WAIC 开发者日,属于开发者的节日。 ! r% Z. p. K1 n* e9 a: B* p* J
/ A# l' \; u/ V! T" Q) _
+ S' f, [6 T3 G iWAIC 世界人工智能大会已于近日在上海开幕。在昨天由机器之心承办的开发者日主单元上,阿里技术副总裁贾扬清、亚马逊机器学习副总裁 Alex Smola、百度 AI 技术平台体系执行总监吴甜、Julia 创始人 Viral、Skymind 联合创始人 Adam Gibson 做了精彩演讲。
4 j7 x1 v* C" O X: j3 O) x- O, j
' X6 n' h0 s( c: ?* @+ P6 z) u( x- Z
阿里贾扬清:从 20 瓦到 20 兆瓦的大脑
9 p. i+ q; S! S6 l 7 U$ V6 Q& }, K) h2 T9 d
' r9 |" Y7 }. a* x
) k: K* c4 ?7 m1 H. j- m9 n3 Z, t2 |从 20 瓦的人脑到 20 兆瓦的云智能,近年来,随着算力、算法、数据的蓬勃发展,机器学习的基础设施也完善了起来。在 WAIC 开发者日中,贾扬清第一个分享了他这几年在人工智能领域的一些探索和想法。
+ N5 d) P+ p3 y! Z5 G5 l) H ^+ Q+ c; O: w3 R* g: u
' n9 Y0 A: `, N# P9 u% I4 r) v7 L$ T2 s9 F( p" Z3 Z
% H9 ^, s5 O) S
% h8 O$ A* [. z+ J" ^贾扬清是知名的人工智能青年学者,在加入阿里巴巴之前,他曾任 Facebook AI 架构部门总监,负责前沿 AI 平台的开发。在深度学习研究、工程、框架等诸多方面,贾扬清有众多为人所熟知的工作。今年 3 月,贾扬清正式宣布加入阿里巴巴,担任技术副总裁岗位,领导大数据计算平台的研发工作。
8 z; E7 c5 {4 N5 d# t( \4 t
( C" G: A/ E* g D3 B3 f$ W' h* T3 l% ]# u8 o; ~; S
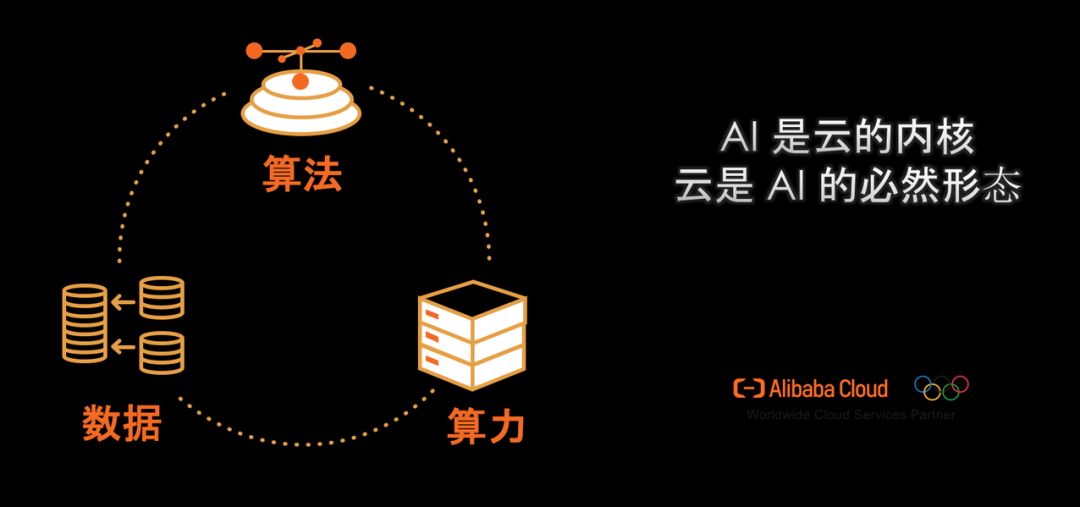
在第一场分享中,贾扬清以《20 瓦,64 千瓦和 20 兆瓦的大脑》为题,从算法的潜力提升、算力的重要地位、数据的爆发式增长三方面讨论了这些年的 AI 发展,并最终表示「结合三者,云是 AI 的必然形式」。" g9 S5 k' ^0 E0 B# f2 j
' ~7 i5 R! V7 c8 e7 e0 W8 Z3 c. f
+ U k; v; W% d, i8 z; {0 L什么是算法的潜力
+ T: U" O, |: t" a9 j0 X5 w+ L' x
% ^9 l- t6 b! s& \
* Y: k3 d0 k/ L; ~0 E3 s人类大脑功率大约 20W,那么都能做些什么呢?这包括与环境交互、学习、推理等等。但是人工智能模拟起来却非常难,贾扬清最开始从经典机器学习算法讲到当前主流的算法,回顾了这些年算法潜力的变迁。举个简单的例子,机器学习需要图像特征,那么最开始是通过 HOG 获取简单的特征,后来发现「边缘」可能非常重要,因此各种卷积神经网络也就大显身手了。* ^* r8 ^( p z. }1 G1 }* q2 `
& l! g0 U8 z. ?; ^/ R
( V# s( N9 G& M* Q6 f# ?( Q
深度神经网络大大提升了算法的潜力,贾扬清举了个案例,在 ImageNet 图像识别挑战赛中,最开始 SVM 等经典算法已经到头了,但那时它们的潜力也只能支持达到 25% 的错误率。但随着 AlexNet 的提出,错误率瞬间就降到了 15%,而且重要的是,这种方法有很大的潜力,之后的研究使 ImageNet 的错误率一直在降低,甚至低于「人类」识别错误率 5%。
! k& @0 t/ g2 j
, o! A$ o+ v9 [5 l! ?5 ^, s8 t# x; E! P7 z
 , ^. U- n. g; w% p, L1 H7 s9 H5 Y , ^. U- n. g; w% p, L1 H7 s9 H5 Y
5 Z* q5 o6 V- u
( z7 r4 V8 I/ q' T深度学习利用强大的拟合能力大大扩展了算法潜力,现在算法问题已经解决了,那么算力问题呢,我们该怎样利用计算系统提升训练速度?, v2 H, o' H& z
. f5 H' h& T. c1 F8 J4 C. R5 L c9 E+ Q o$ r/ U
为什么需要算力、数据
/ G% M. q" i6 \$ v7 j: L2 p$ |: L: |$ e! s$ W4 y) h5 P
* ~) L4 B8 R' y# P/ r人脑的计算速度是有限的,但计算机可以通过堆算力来提高计算机系统或机器学习系统的能力。在这方面,人们一直在研究如何通过系统的方法提高训练速度。( c& P3 x0 K& r5 g) z7 v1 T9 o
, s9 x/ W: Z$ @7 D
" p/ G' u4 U, F/ v& X, u. @2 h2014 年,机器识别一张图片里的内容要花 13 微秒左右,但今天,这一速度已提升了上百倍甚至上千倍。这一提升得益于 GPU 的聚合:单个 GPU 每秒只能处理 230 张图像,比人快不了多少,但 256 个 GPU 聚合在一起却可以处理 6 万张图像。因此,我们可以通过大量堆算力的方式来提高训练速度,这也是大家前几年不断努力做的一件事情。而这些 GPU 又通过分布式训练的方式进行合作。- r# x" ]- m! j# i* C `
?1 M5 d- }, K; C
" l& {- z1 Y. h# o
. V+ q1 L4 n1 [& D
; ]3 h& ?1 C! ]$ N- Y0 d( e( R& h& O* F, @- S
如果说算法是潜在的能力,那么算力就是发挥潜力的保证。但是,算力将训练速度提升之后,模型的复杂度也随之提高。而模型越复杂,过拟合的可能性也就越大,因此我们还需要更多的数据来缓解过拟合。
l: n. x$ k: [0 u* ]# [" W0 `+ ?+ c$ G) ] j
& T# p. D4 p0 q9 ~从 1989 年至今,训练模型所需的数据量也经历了爆炸式增长,从 MB 到 GB,再到 TB 和 PB。9 H! I' j: E; V# S6 `
# X. Q* V' G5 ]/ s
! S6 `+ v0 y& c! b/ y/ d( s, z$ K# n # T% m! ?, a( ^ V8 W. X! N, } # T% m! ?, a( ^ V8 W. X! N, }
% \* q% K. n$ h9 d/ y: w
, U8 a! S9 @7 Z- V6 x: [/ D
20 兆瓦的大脑 Y* p' k0 m8 b3 G
2 s7 O0 a' a0 \. \; M; z" J
' h( l' l! @9 |0 P有了高效的算法、海量的数据和庞大的算力,那么怎样才能将它们聚合在一起并应用到实际业务中呢?贾扬清表示,很多科技巨头都是通过云的方式来解决,也就是通过 20 兆瓦的大脑解决。' O; V8 p2 S) y0 V; o& g
! L8 N* z# |# \! C, O, I3 Q# ?$ F' v3 N; s. C, h
贾扬清说:「为什么我们说只有通过云这种模式,才能够实现机器学习的创新?是因为云向我们提供了更大的规模、更高的可用性、更强大的安全性。」
! @0 v6 l" ~+ e! ^8 e
, ?; S; Q/ P& F! @+ ] J. v8 `) u* x0 R& t" l) \
5 j" h W. I2 p: v4 ]% l
; ?3 U- d4 i- ? k; T; c5 w9 {$ g% {1 x1 G
此外对于公司来说,我们关注的应该是业务,而不是基础架构这些东西,所以云能很好地解决这些问题。贾扬清说:「从 20 瓦的大脑到 20 兆瓦的大脑,我非常高兴的是我们一直在解决各种问题,希望联合算力、算法和数据,从而不断趋近于真正的智能。」
! e+ |5 m- {" R! v: A
& {/ a7 _: D0 Z4 k$ { N
G; Y2 `9 `% g. Y3 d& k G「AI 与云的结合是一条必经之路」,贾扬清总结道,「我从一个研究者开始逐渐转向了工程、转向了业务、转向了更宽的思考范围,从而将 AI 向前推动地更远,这是我非常兴奋的一点。」 J s0 w' ^) r% u3 d
6 g6 c+ K1 ~# @ X7 P
$ u) a1 _; U y- \: N
亚马逊 Alex Smola:深度 NumPy 与深度图学习 ( d0 \" X1 m$ E" ~% {
4 b; f S" I" }3 n) N' {8 p! a8 P+ \( }; K
NumPy 差不多是所有机器学习开发者必须了解的库,它为 Python 附上了数值计算的「灵魂」。然而随着深度学习框架的流行,NumPy 似乎已经不再闪耀。那么我们是不是能为 NumPy 插上「Deep」的翅膀,用 NumPy 的 API 直接构建并训练深度模型?这就是 Alex Smola 为我们介绍的 DeepNumPy。
$ R1 \5 `5 z+ H" {7 Y( s/ [5 ?( _% X0 A$ k9 l
5 m8 r1 f/ y. B! }: n+ Z8 }! b1 |

9 M* P9 i1 h3 C1 l6 f2 N- M, [) D: b( X. ]) @' _" X
. q% L" [) ~- U- t
除此之外,Alex Smola 在开发者日上还重点介绍了图神经网络框架 DGL,它与 DeepNumPy 共同为开发者提供最好用的工具与 API。
U; w M9 p+ B7 Q' p* _9 B% R
2 ~3 _% L, ]8 N" _5 ^9 @
8 y3 x% R+ l5 ]Alex Smola 于 2016 年 8 月加入 AWS,现在是 AWS 副总裁和杰出科学家。Smola 被公认为世界顶级机器学习专家之一,他在 2013 年加入 CMU,并担任教授。Alex 是学术研究界的一位多产且被广泛引用的作者,撰写或贡献了近 500 篇论文,引用量达 75000 多次。
' D# A2 L7 a h2 s& [# c4 Z5 F
* Z! P9 v6 Q9 x& `5 ~/ u" y! V0 D* q# w, Q/ U _& _! |; T
下面,让我们看看 Smola 大神在 WAIC 开发者日上介绍的《Deep NumPy and DGL》都有什么吧。
) v1 R6 w" v1 }1 F
) b+ N: \( S; X* x
+ n1 e" k' d l2 _" F! jDeepNumPy8 v! Q1 J6 @5 }7 K+ g/ B6 ^9 R
" g9 m# x- O# y# H, H# _: j6 O5 A! z6 }
Smola 先让我们思考思考,到底机器学习的开发流程是什么样的?这时候我们就会发现 NumPy 即使在深度学习时代,也有非常多的应用。我们习惯了在预处理时使用 NumPy,在预测和可视化时使用 NumPy,甚至在不同模块间传递张量也用 NumPy。除了核心的模型搭建与训练,似乎其它流程都能用 NumPy。
( {. o! `0 t0 q! Y" |
5 Y3 N* y4 C1 Q# E, l- L8 W
6 |% e+ g# a# y% s8 W2 x
- c5 [+ k2 m. V q! K. F
6 y( W9 Y5 n6 ]3 B; w3 t0 Y
" X) U( ^- l+ l! n- {6 y6 a+ B) @那么 NumPy 既然在矩阵运算、数据处理等需要 CPU 的环境下如此强大,我们为什么不直接将它迁移到 GPU,并赋予神经网络 API、自动微分等能力,这样不更方便么?Smola 表示,MXNet 社区正在做这样的事,希望构建和 NumPy 100% 兼容且还能搭建神经网络的工具。+ B. m9 f' C& V# ^+ {6 K$ Y
8 i% V. B; o* n) G6 d% P
4 L. o7 M! R* f9 O6 y9 R8 ~' L- l. T4 a4 ?- S
& K- o8 [0 s/ A1 t6 I简单而言,DeepNumPy 作为 MXNet 的前端,它提供了类似 NumPy 的接口,且包含了一系列用于扩展深度学习能力的模块。DeepNumPy 主要包含两大部分,即 mxnet.np 和 mxnet.npx,其中第一部分用起来和 NumPy 是一样的,第二部分会提供更多扩展运算符,对深度学习更有优势。" \2 P5 C9 g) I3 j. w3 a9 k$ D
9 M4 s& ?8 Y; J! f3 \" o
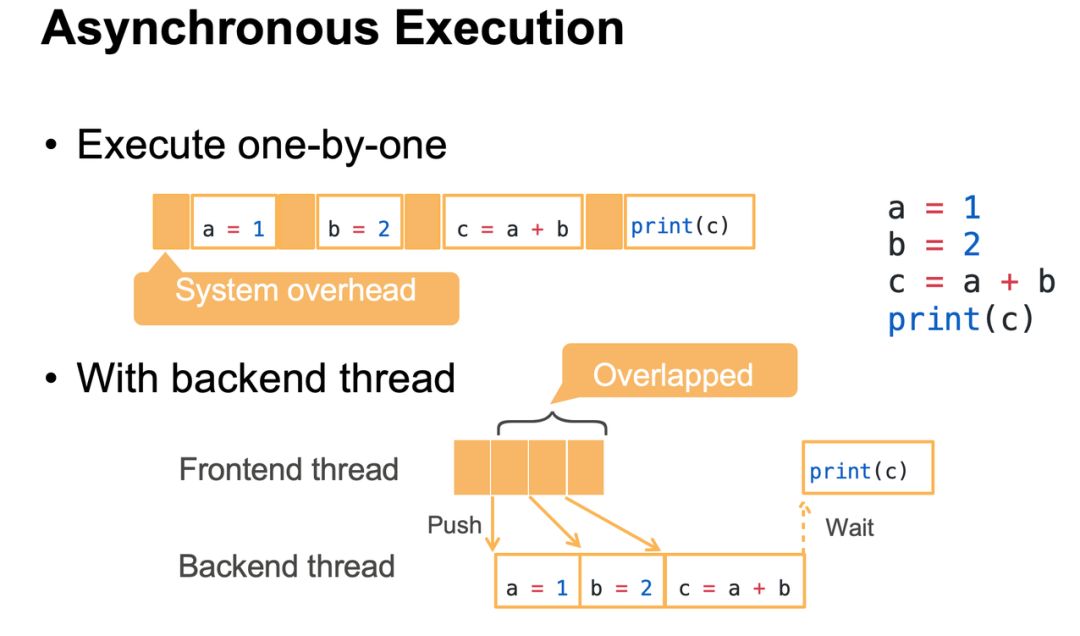
; U% E- P" b0 ?' v) X0 U+ I& `3 u如下 Smola 在开发者日中主要介绍了 DeepNumPy 的两大特点,即异步执行与自动并行化。异步执行的优势与过程如下图所示:
7 X/ |' f6 z7 e0 j4 c% \5 t; D& K1 B6 J; F) g; a
7 ?: ?7 y# i* Y# q5 _8 @' [
; w! G! [8 o2 J0 h8 ~8 a1 P
. t7 x: y4 a+ {
6 d3 c9 c0 o/ M; C# W/ ?3 `一般而言,我们写的语句是一行行执行的,且系统的成本也会和真实运行加在一起。DeepNumPy 的优势在于,后端会以异步的形式处理前端运算。' q0 s$ L. E2 y! Z' y
5 M+ u# o- \' g/ q4 v
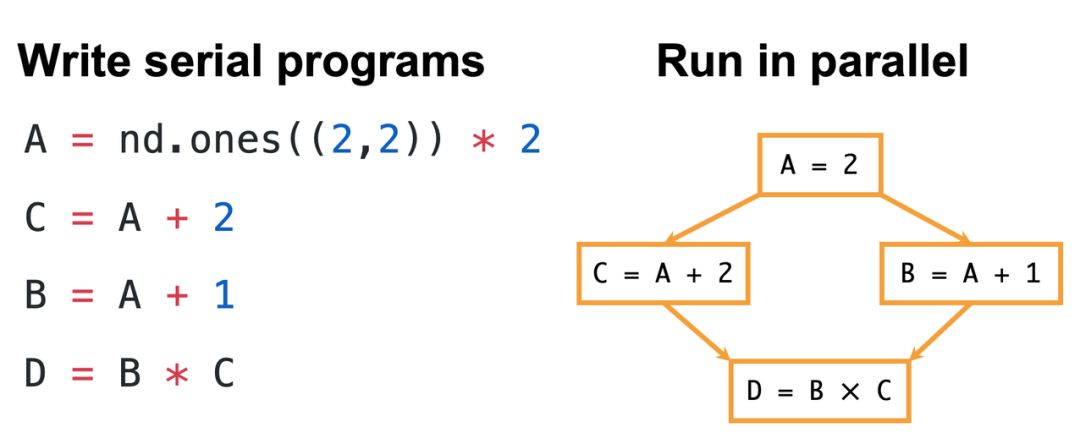
, w0 }0 K7 r/ O L/ i9 E3 b' ESmola 表示 DeepNumPy 另一个优势是自动并行化,它可以自动解析不同变量之间的依赖性关系,然后优化运行路径。如以下例子所示,即使我们写的是一行行代码,但 DeepNumPy 可以将 B 和 C 两个不相关的变量并行处理,从而大大降低了运行时间。
; b- L h3 Z, t7 Q
' |4 z' t) E i8 L6 M" ]/ [: k4 ]. {& i; W2 D$ v" r% o: r6 a
 + X9 i+ r3 b& j + X9 i+ r3 b& j
! }& ?* [" p {" u
0 N/ N9 a7 {* F# j* b+ b
Smola 总结道,DeepNumPy 在 Apache 开源组织的管理下,将继续修改各种 Bug、提供更多强大的新特性。目前 DeepNumPy 已经在通过 TVM 优化 Operator,以提供更多的便利,包括支持 CPU、GPU 和 ASIC 等其它硬件。此外在性能上,DeepNumPy 经过 OP 融合与定制化的调度机制,它即使在大模型上也能展现出非常优异的性能。
3 k' g: t* R. u* X1 b- @6 @ }- [" k( @2 s, ]
! g4 L+ r4 i- ~( V0 D1 V
在听过 Smola 的介绍后,机器之心也查看了这一前沿的开源工作,虽然目前 API 文档还没有完善,但从一些案例中,我们发现它的使用方法真的和 NumPy 一模一样,不论是创建数组,还是执行索引、运算等常规操作,都有一股熟悉的味道。3 q0 {6 D0 s8 T7 T8 {! d
; b8 I" ^& d7 h- i; V& p
2 S; \ ^% Q! ?) ^, j8 R( |
Deep Graph Library/ c2 U9 C& `/ M& @2 m
, v# h7 ]7 |# C4 o4 \) l0 E8 l- a9 K1 z/ F
Somola 另外重点介绍的就是深度图学习了,这也是近来非常受关注的研究方向。机器之心之前曾介绍过 AWS 开源的 DGL 库,那么现在让我们看看 Smola 眼中的深度图学习是什么样的。4 o; p: C6 Q# e% ?9 e5 |/ A
! {$ _5 T i2 k4 |
: }3 q( N# y% k3 `) ?1 b+ \* a
首先 Smola 先定义了什么是图(Graph),以及它的一些应用,例如社交的推荐和欺诈检测等。图之所以这么重要,很大程度上在于它的表达能力,现实世界上很多数据都能用图来表示,差不多是最重要也是最通用的表示方法。然而深度神经网络擅长的是图像等非结构化数据,它基本上处理不了关系型数据,这就要求「图」算法有更新的发展。
. ~- u1 g; d( W* n+ g; B. W3 N" z4 B N
1 L5 B1 X s* Y& @' v0 M7 `7 Y
' W {0 b6 M: s) ~$ V, t0 v: r) N1 G" O8 V( \( X$ e
5 |0 S3 M; {5 _3 r6 tSmola 说:「DGL 是一个 Python 包,它为现存的张量数据库和图数据提供一个高效的接口。」为了完成这个目标,DGL 必须能兼容多个深度学习框架、必须提供最精简的 API,同时还要高效地并行图的计算。据 Smola 介绍,目前 DGL 已经支持图卷积网络和 TreeLSTM 等多种网络,也适用于很多应用场景。
. `0 U$ T4 ^' K& o' E* Q0 h! x" s+ B7 z! Y/ `2 p
5 d. ?9 G3 A7 m/ d2 J) ]- r6 u, _
Smola 举了个 Pagerank 的案例,它最开始是一种对网页重要性进行排序的算法。Pagerank 本质上是一种以网页之间的超链接个数和质量作为主要因素的排序算法,因此,我们也可以将网页视为节点,超链接视为连接的边,这样就能构建一个标准的图。9 Y0 _( o" X9 R
' G8 O u1 r7 v* \
m& |6 ~( e! L) U如下所示为 DGL 实现 Pagerank 的代码,它的构建过程非常简洁。/ I- P% A( X% g1 [- t/ P9 \" f* B
# f4 e9 p* F; J q
5 L6 I; H% c) ^/ G
" G4 \( l$ Y4 j: w; ~% s9 [% I
7 _# X" E, Z+ [
4 E [% J8 l) r- }7 k$ }7 ISmola 在现场还展示了更多用 DGL 建模复杂网络的案例,包括图卷积网络和 Tree-LSTM 等,其中非常有意思的是 Transformer,DGL 也可以将它分解为图,从而扩展它的能力。
) J" x% D8 k f" X) @, E
1 v2 p$ _4 V' t9 g
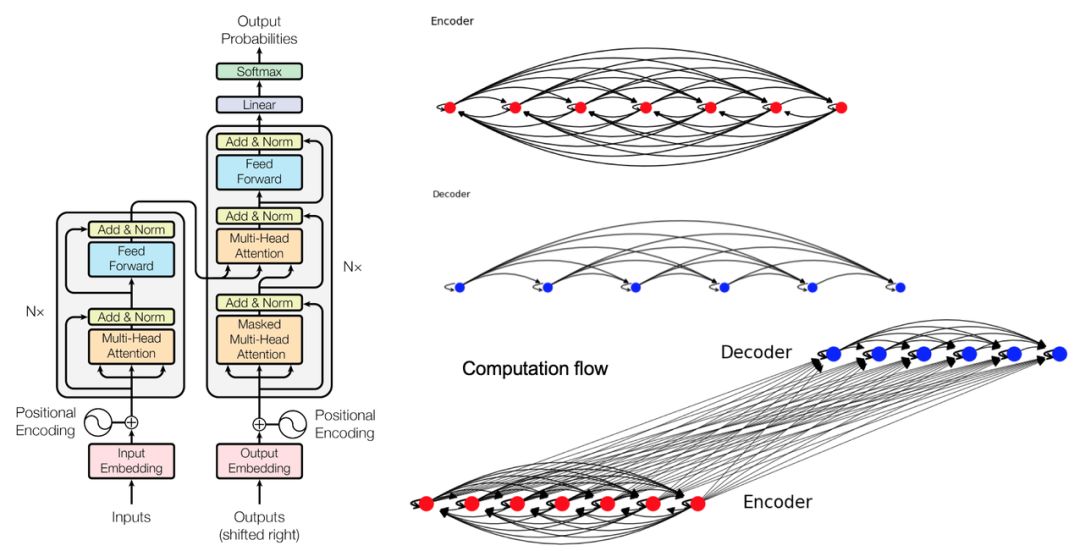
' B/ b; [7 {# d' y, D4 O( x下图展示了 Transformer 如何解构为图,Smola 说:「我们可以将注意力视为图中的边,并采用边上的消息传递机制作为对应的运算过程,这样我们就可以将整个 Transformer 表示为图。具体而言,Transformer 可以由几个子图组成,其中 Encoder 建模的是原语言图,每一个 Token 即一个节点,不同节点间通过注意力进行连接。Decoder 也是一样,它建模的是目标语的图。」* V- S& x1 y' ~- h, p, Y. F: X" f) f$ d
; e2 R& w* n4 w0 |/ M
, ^7 Z* ~* h( Z; Z" n' Q& Q
 + w' t: {- h) w( U; j1 ^, M + w' t: {- h) w( U; j1 ^, M
}6 X$ I! t& f/ i
" i3 ]( C# C1 {$ m
Smola 表示:「目标语的图是半完全的,也就是每一个词只能注意到已预测的历史词,它和原语言的完全图是不一样的。最后 Encoder 和 Decoder 相结合就能生成完整的 Transformer 图。」) I2 ^' S; c2 D: k
9 V) r, D! D3 B% }6 ^; ~+ ^
2 {! i& L7 S! U. N1 b
总体而言,听过 Smola 的演讲后,我们感觉图的应用要远比想象中多得多。像图像或文本这些一般神经网络能很好处理的数据,图神经网络同样也可以,甚至计算上有更好的优势。
9 |' R8 P/ H# x; }* Z' n
/ r0 G! Z, A) M, T5 ]" r; ]# q9 s! D* k
百度吴甜:语言与知识技术产业应用创新与实践 ' W! e. [; i$ E; I- N
& u* v; y; c0 Z, a! n4 i/ O. u- |3 Y8 D& D) M1 w
以技术落地为落脚点,在本次 WAIC 开发者日上,百度 AI 技术平台体系执行总监吴甜为我们带来了主题为《语言与知识技术产业应用创新与实践》的演讲。& C1 c8 x1 w) u' |
9 y1 B1 _; G6 h" J. F. D& K8 T) T* N6 g. C6 c4 |

5 L E8 o4 I# k* [
" R" r/ [$ R' d3 ^+ l) [6 T/ X- N0 W4 U5 L. j; y5 ?1 k2 E
吴甜现为百度 AI 技术平台体系执行总监以及深度学习技术与应用国家工程实验室副主任。她主要负责百度自然语言处理、知识图谱、深度学习技术平台飞桨(PaddlePadddle)、百度大脑开放平台与生态等。7 e$ I H+ j1 h0 }4 b7 U- \0 w: K
% l3 Q* r# e! y' p3 L4 B% ]8 |
' K% o1 X' n9 W- u) T0 i9 z; {. Y百度语言与知识技术布局、发展历程和开放场景
" `: T! J1 [) g- T. D5 W5 O
7 g2 X+ T+ l1 X# R' d7 t6 E _. c, D0 E' J
吴甜开始逐一介绍百度语言与知识技术布局,其中底层的知识图谱是基础,中间层是语言理解和语言生成,最上层则是智能搜索、深度问答、对话系统、智能创作和机器翻译五个应用领域。 a5 H% s$ P9 j1 F. o2 h
. u# d2 C3 d7 P- \: E- L5 ]) X: {2 q9 k) Y! L# L& S
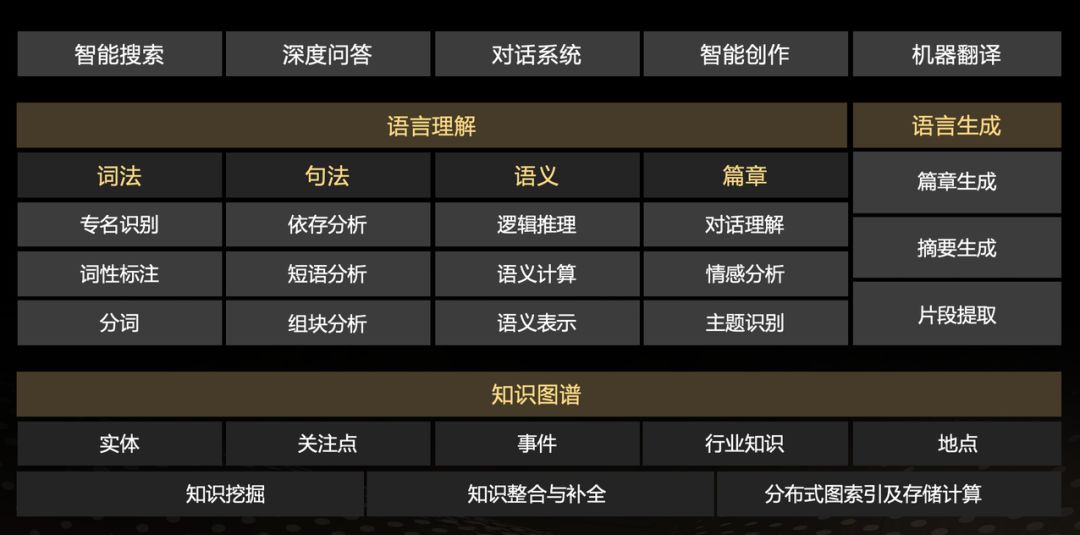
. h& ?: h5 R: c百度语言与知识技术布局。 0 a- g$ @: f3 h: f7 d
- r5 x% f; _& c( G( R5 t5 C" ~
i5 R% L Q0 j& P' h
这样完善的布局,它的发展也是有一些过程的,吴甜表示主要可以分为三个阶段:第一阶段始于 2000 年,主要集中于技术模块的集成;第二阶段始于 2014 年,开始将技术平台化;第三阶段始于 2017 年,开始开源开放大生产平台。' V3 x9 i# b i4 L0 D1 I
' J! w. t W; d
s. h1 y! Z( } L+ A2 d那么百度大脑语言与知识技术开放全景究竟是怎样的呢?如下图所示,最底层是深度学习开源框架和平台 PaddlePaddle,倒数第二层是语言和知识领域的各项基础技术,往上是四个应用级平台,再往上是四种服务方式和各种场景方案。( I) ~& a0 T8 O. p0 S3 T% A
7 ]4 Y9 X' _6 i* L2 x
% A& A8 ]' E) X+ C }: T
 / z* P b/ P1 e& o. e, v$ G / z* P b/ P1 e& o. e, v$ G
百度大脑语言与知识技术开放全景。) p. H" o, X6 L, [ T; F% B
: _7 o- Z" c5 V7 {) [$ M! p2 S2 k
9 h( M y `( ]% m8 M& G% @3 g. e6 M$ L百度在 NLP 又有什么样的重要成果?' E' M8 I( T# E; q* Y2 q; }
@5 h' d& @- A1 j8 @. w; I$ l! h: @5 I' [# r
百度在自然语言处理领域的重要成果包括语义表示预训练模型和今年 7 月份推出的持续学习语义理解框架 ERNIE。吴甜表示,ERNIT 已经累积了 13 亿+知识,其中包括 1500 万篇百科语料和词语实体知识、10 亿条网页搜索知识、700 万轮人类对话数据、2000 万对句子语义关系和 3 亿组篇章结构关系。9 h8 m3 A9 d1 V* \: w- Z
5 S. L) K# h, a$ S5 E: C! d0 }2 M. L: ^" a! X: f9 @% F
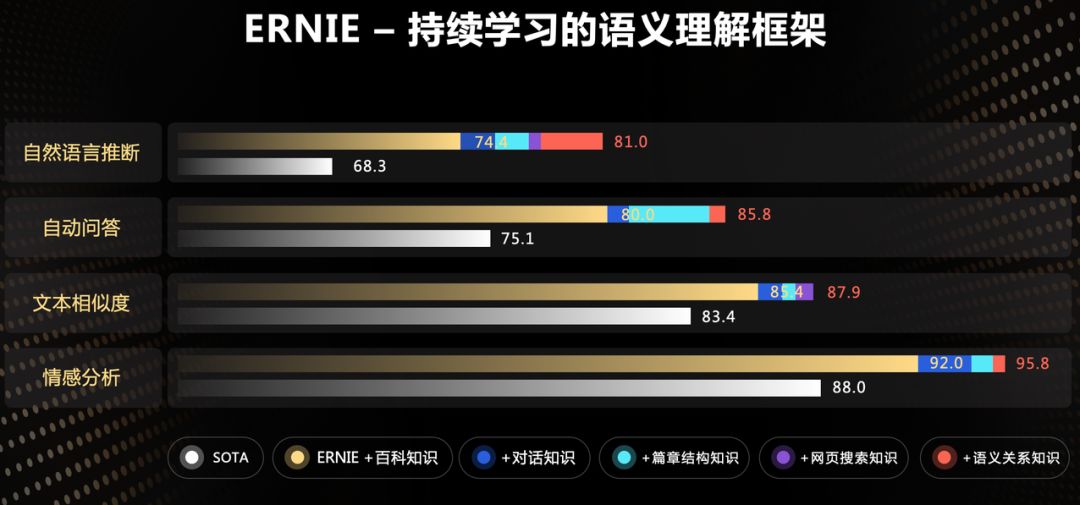
8 ]9 t! R8 A- y( q/ I' A% P持续学习的语义理解框架 ERNIE。 / g2 w4 F9 |% e4 }/ [$ Q
) K/ I- e+ v+ p9 W( N- W
9 U8 m, N* C: C; fERNIE 框架在工业应用上又有哪些效果呢?首先在智能问答场景中,如果将 ERNIE 模型应用于问题的分析和排序上,召回率就能提升了 7%;在加入 ERNIE 模型的情况下,广告的相关性也提升了 2.7%;ERNIE 模型能够使文本润色的准确率提升 7.3%;在对话理解场景中,ERNIE 模型将准确率也提升了 2%。
% V/ |% v u) c, i' H0 u$ H
! D5 p, [' [, X* U4 w
& F, E4 f- s9 e0 s# j8 N( ]& E0 k+ H, [PaddlePaddle 深度学习平台
( D$ N, K/ O8 V, W& w8 Z m
. E4 ?. U# S9 V4 [/ a
) d, f8 g0 `, V+ R; l: |但是要训练 ERNIE 这样的大模型,非常重要的一点就是提升训练速度。因此,百度推出了基于 PaddlePaddle 的 GPU 多机多卡训练加速,从而使得基于飞桨训练 ERNIE 模型多机加速比达到 77%。
9 d# G6 q- ?6 w5 m, r) A; ^ w3 u g6 ?+ p" D) E$ Y" \6 ]6 ~7 s
$ k4 B) d! j& [: `3 cPaddlePaddle 以深度学习框架为核心,从数据预处理到模型部署为深度学习的整个开发和应用流程提供了完整的工具。其中核心框架是从头构建模型的基础,而工具组建可以帮助我们快速训练与试验模型。最后的服务平台会为开发者提供整体流程支持。
5 [9 ]8 K. @, g7 y8 a1 }5 m
" C4 u! v0 v/ G4 g5 u ~
- e' w5 k2 |* q" {+ w$ f. M4 h 4 B+ D: y$ {9 S0 F* @$ e 4 B+ D: y$ {9 S0 F* @$ e
: |9 c; X3 z4 Y! k% y
: B$ Q) Q/ q! g: q) n* B吴甜后面分别介绍了一键加载工业级预训练模型百度 PaddleHub 和面向工业应用的中文 NLP 开源数据集 PaddleNLP,后者提供共享工业级骨干代码,能够轻松适应领域需求。它们都是以飞桨为核心框架,并扩展它的能力。5 m4 o/ @1 v; x: ]
# e5 I8 ?# o/ t; g
0 U+ K5 N) ]3 A. m, |" j9 P在 DL 平台和基础技术之上,吴甜以 UNIT(理解与交互技术)平台为例,介绍了应用级平台智能便捷性。UNIT 平台致力于打造为对话系统定制的专业、低成本、全链路的技术与服务平台,并已经为金融、教育等行业提供解决方案和服务。# F4 e7 L" _: H, e, N6 L
, R$ t Z% E# r4 f- I' E1 y( N4 j8 \7 S
UNIT 平台核心技术包括语义理解、阅读理解和对话管理三大部分,其中 ERNIE SLU 可达到在同样理解精度下标注量降低 37%~72%,DataKit 可使数据生产效率提升 8 倍,使用语义理解 SLU 定制可使对话技能综合研发成本降低 60%。目前,UNIT 平台已实现 6.8 万定制技能,累计交互次数达 570 亿次,全面覆盖智能客服、智能出行、智能办公及其他智能交互场景,为一线开发者实现 AI 产业化提供有力工具。
5 u5 J6 z2 p1 s) H4 l* }# V4 d- ~- }. q
$ o' |. B9 `) h' [+ \& x/ {# v
总体而言,百度的语言与知识技术就是在飞桨深度学习平台上,搭建完善基础技术和应用平台,从而构建更强大的 AI 基础设施。
2 q6 T, O/ C5 x0 Y# T
& w4 X1 h" g/ a* N
) U) b5 e" [' @5 Z& oJulia 创始人 Viral B. Shah :天生支持可微分编程的 Julia 1 J- Y. U% D/ @2 ]* L2 d# O; Q
) [6 ^% S& k9 n6 G
1 `0 h: x3 ^& v6 Y1 C3 t
去年 8 月份,MIT 正式发布了 Julia 1.0,在开发者社区引起了很大的轰动。该语言旨在结合 C 的速度、Matlab 的数学表征、Python 的通用编程与 Shell 的胶水命令行。那么,Julia 语言以后该怎样走?Viral 在开发者日表示,只有内嵌可微编程系统,Julia 才能更适合深度学习开发,适合更广的科学运算。
) p% r' ~3 X8 @9 g' E, r
8 M$ O0 u* s5 l" v1 n
8 v0 ?6 o, B) X& y7 q
6 R" S' w3 g0 w9 E1 A9 ?
8 D4 t6 H8 H, R7 e. \8 T3 R$ r! y& }0 H2 o4 k9 M4 P
在本次的开发者日上,作为 Julia 创始人之一的 Viral B. Shah 博士重点介绍了为什么 Julia 适合做机器学习开发,以及 Julia 在科学计算与机器学习上的可微分编程探索。这种机制将内嵌于 Julia 语言,且因为没有中间语言的转换,它做深度学习、做反向传播的速度还要快于 DL 框架。
5 Y/ V) {+ f! Z; i: D- J# u: O5 P4 U; n' t+ Z8 j" q
: p4 | n" ^4 D) ?' w' pViral B. Shah 拥有加州大学圣巴巴拉分校的计算机科学博士学位。他是 Julia 语言的创始人之一、Julia Computing 的联合创始人兼首席执行官,也是开源程序 Circuitscape 的作者之一。
0 b0 {) A. G& u' M- ?$ |- | t r# W* a2 [1 q% \8 a/ U2 ~
0 h1 G* B" \6 b% v% q' U拥有如此多的研究和开发经验,Viral 在开发者日介绍的《Julia: Generalizing Deep Learning and AI with Differentiable Programming》一定很有意思。
- m8 o" B9 W: [$ N' r
4 A- I! z) ?0 y8 z0 J5 \2 _7 g4 Q
9 _7 z( y, e. |# Q. Z& D" s9 D为什么 DL 需要新语言
: W+ d, l% M. X$ C& U0 {$ x2 G+ e1 \7 P0 c' ]( E$ P0 E5 ^7 l* a
8 C0 e4 |! R! W
Julia 在中国已经有非常成熟的社区,它的性能优势也不可忽视。Viral 通过大牛的 Twitter 展示了为什么深度学习需要一种新的编程语言,不论是出于性能上的考虑,还是出于编程模式上的考虑,一种更专注于机器学习的语言都是有必要的。这种语言应该内嵌可微分编程的思想,并提供便捷的模型 API。
/ h. A( u9 A! x; H( |: J6 C( M4 f8 f3 y, W; [4 N. {0 h. p# Q" R& p
& g6 y$ G) e+ i* S7 c" C
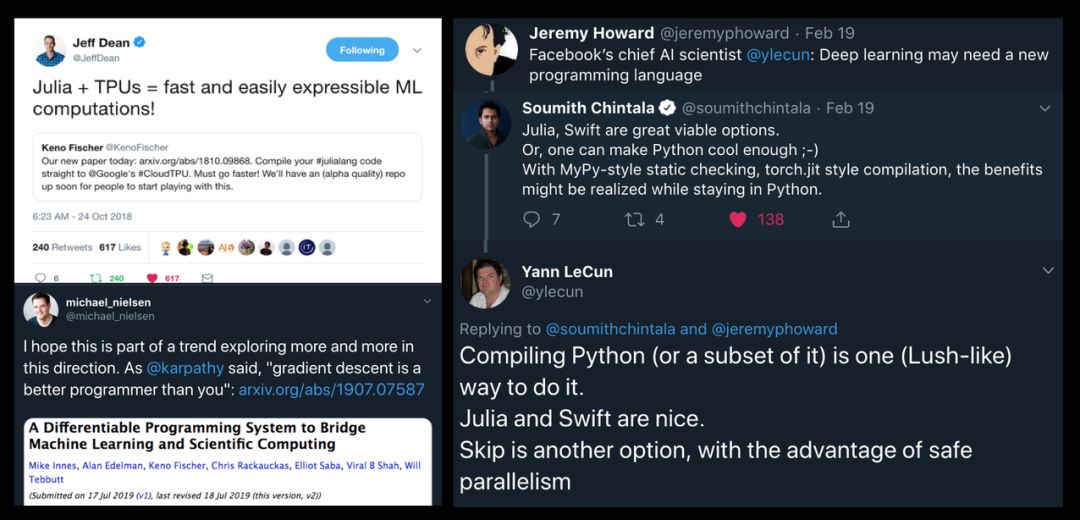
! U! E) V" Q6 Z9 U& S9 Y9 p$ H3 E' U+ K/ s n% c
8 a7 B& M6 K2 f& u2 b7 MJulia 的可微分编程是什么样的8 A, x# V7 T% b3 J- F$ b
9 ?9 N$ X9 J" s* i, ]- V5 U8 o6 R+ f+ F
Viral 说:「我们最近也发过相关论文,尝试建立机器学习与科学计算之间的桥梁。这个名为 Zygote 地可微分编程模块将内嵌于 Julia 语言,并作为第一等的特性。可微编程最重要的特性是执行 source-to-source 的转换,自动微分转换基本上没有运行时开销,因此它要比反向传播的实际计算成本低很多。」5 k5 w6 Z' q' q" T
f- k, |* k( k$ Z; T& u1 Z, _
# n) ^- {5 |4 v如下所示 Viral 介绍了可微分编程与一般的编程有什么不同。* Z7 c) l3 X. S4 B
4 C3 j8 u) E. d W/ G/ \
* T5 l" l) b& L4 `9 c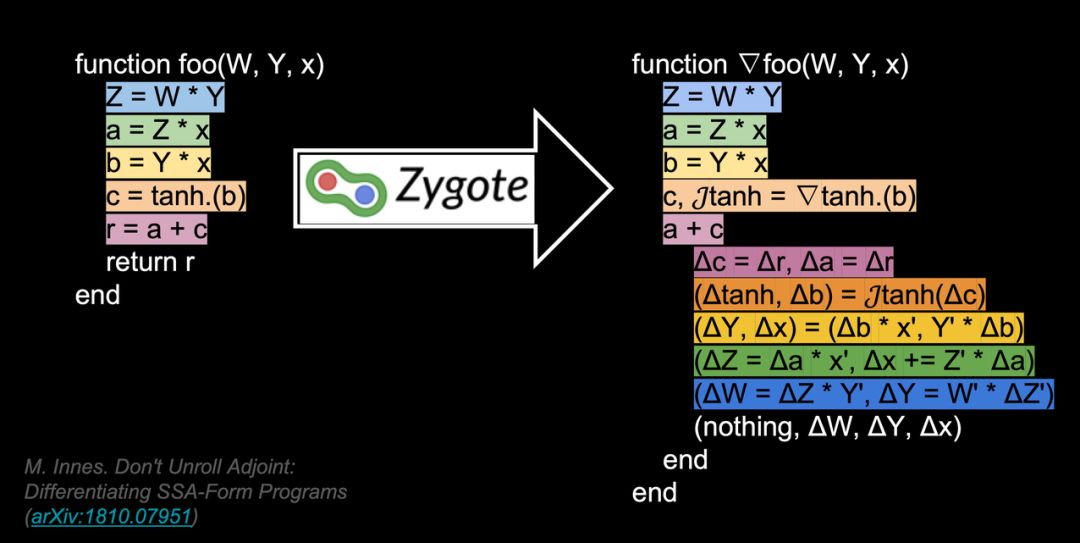 ( B- c+ B! U& N, V% D ( B- c+ B! U& N, V% D
1 x2 } Y' c$ J( O5 {% v9 |7 i
& h! A; D+ c" z; A; @
Viral 表示:「Zygote 可以对任何函数进行数值计算与梯度计算,只要我们如平常那样定义了函数或高级函数,那么 Julia 和编译器就能自动算出梯度。这种梯度可以用于进一步的运算,例如反向传播或梯度下降等。」这是 Julia 非常重要的一个特性,它能处理更广泛的任务,例如应用物理学或分子生物学等。
2 h5 I0 P% k5 H/ X- F" e1 w' w. {; E) m/ f& P+ M
: ^+ Z# l$ Z! d* t! A4 ^
「不止机器学习,其它广大领域的科学计算也需要利用这种可微分编程的优势。因为它们之间有很多相似的地方,例如都会使用最速下降、拟牛顿法等基于梯度的方法,都依赖线性代数等等。」,Viral 强调到。
- h g# O; M& `7 A* G1 |7 p
* U% Y: k+ v! P; Z
# m8 G6 D3 _5 q0 ~+ A. u后面 Viral 还介绍了 Julia 与可微分编程的众多案例,如下主要展示了微分方程的应用。
; Q3 W1 |& i" ~) I' w; W4 G) |3 q) j. E" k" j2 k4 s
# x; v6 O0 v9 k! q: g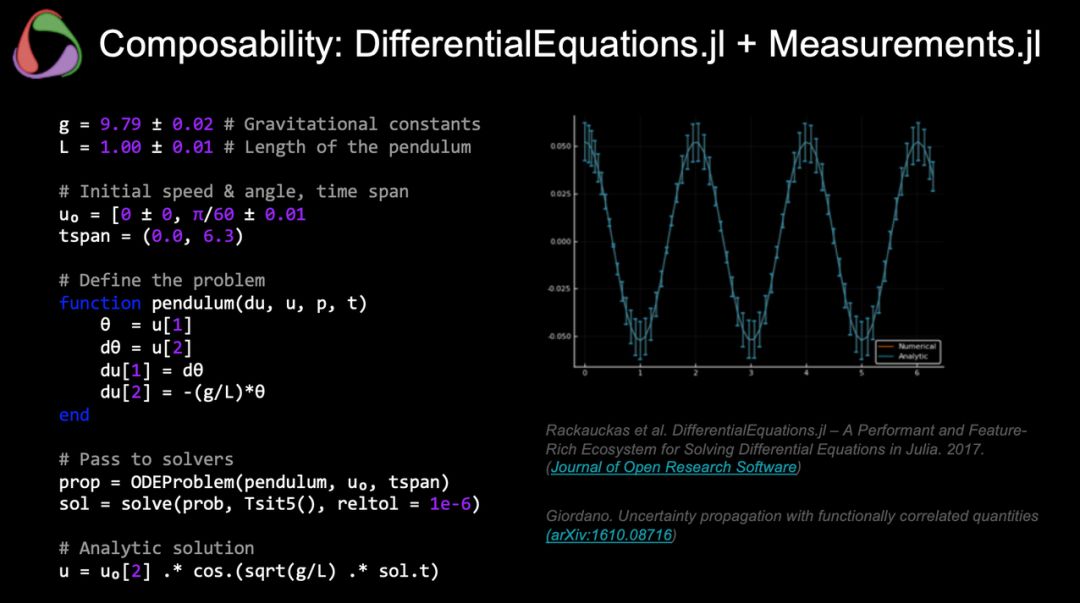 ' h) L. i4 L( C }8 h. d- A ' h) L. i4 L( C }8 h. d- A
m+ A9 f' v3 Y/ N5 p
; |7 T* r& B- V# b
Skymind Adam Gibson:AI 对第四次工业革命的推动
( Q# a$ A) I5 q* I9 { k# `4 u& F
* j4 @* a6 q' w+ y1 ]
5 Q* G+ b7 e9 k自 18 世纪以来,人类社会先后经历了三次工业革命,从手工时代逐步过渡到蒸汽时代、电气时代和信息时代。而今,我们正在经历以基因、人工智能和清洁能源等技术为突破口的第四次工业革命。其中,人工智能是推动第四次工业革命进程的一股重要力量。
8 f2 X6 u$ D9 [0 _
! Y8 |- F) h" T, u/ C
/ J. W& z+ f; H& ?在本次的开发者日上,美国人工智能/机器学习公司 Skymind 联合创始人兼首席科学家 Adam Gibson 做了主题为《The Driving Force behind theFourth Industrial Revolution:Emerging of AI in Industrial Applications》的演讲。( C F2 `( U1 n& B8 q" `" C
! n$ |( N( ]3 E; i) y) v5 Y, }5 i* H# L
 0 n1 e% X9 m) ^# Z 0 n1 e% X9 m) ^# Z
除了创建 Skymind 之外,Adam Gibson 还是最广泛使用的开源机器学习库 Eclipse Deeplearning4j 的创建者以及旧金山 Galvanize 技术学校数据科学硕士课程的顾问。 / {* L) \$ D2 g( `8 A- Z
& b8 s9 }+ W5 n/ C9 \/ q
( d+ b5 e# k, ?+ J0 J
Adam Gibson 在演讲中指出,维护、维修、人机合作、生成式设计、供应链、产品优化、网络安全等都是工业 4.0 时代的推动力量。
0 P: |# m1 L; [6 ?1 R& ~
d" `$ u! B8 e9 ^: f: r3 U
9 v# E1 o1 b& V. g; n! V企业中的 AI 应用现状+ B/ Q) U: k+ G% g9 ^( r0 a
3 e& ]4 X W4 l' t
; ~- [0 b2 A, y& b
既然工业 4.0 的实现离不开 AI,那么 AI 在企业中的应用现状如何呢?Adam 指出,目前全球通过 AI 获取价值的企业还不到 5%,而且这 5% 的企业对 AI 的利用也大多不够充分。其中有些中小企业只是听说过 AI,但没有人才或资金来帮助实现 AI 的利用,还有些大公司声称自己用到了 AI,其实用的只是上世纪 80 年代的认知系统。只有极少数 500 强公司或顶尖科技公司才能足够的人才、资金利用先进的 AI 系统,并利用其产生价值。! b- p2 y9 t: O+ V
5 k3 l- N# D. ^$ w/ Q
) K4 S" ^% y5 `; o& J; q7 s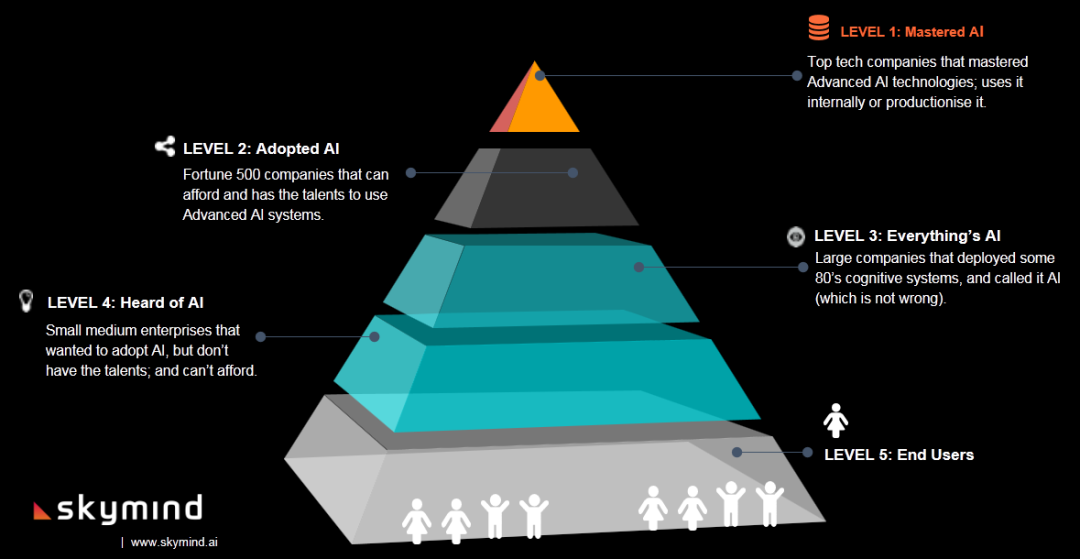
* O% L, e+ ]8 {: k- l! ]! Z7 {/ P3 ?" R8 A, x
+ X4 T h- @: ?& x. | 此外,Adam 还指出,我们现在要做的就是降低 AI 的应用门槛,通过多样化的处理将学术研究成果转化为更加实用的现实应用。同时,我们还需要看到市场需求所在,还很多论文忽略了这一点。9 _9 N/ N9 T$ L( ]' N/ }& G
4 C* _) Y& [& K+ K+ _( H( J+ [" j
) ~/ s) x# h, E3 e- h+ P5 ?如何在工业 4.0 中应用 AI?
" E3 [' L6 ~, {( {2 b8 o/ z. n W) Y8 \) \9 g; d( U, S
% C7 _6 Z1 x) ^# a7 ^3 C5 Y8 F
除了上述人才、资金等条件外,在工业场景中应用 AI 首先需要解决数据问题,因为这些实时响应的工厂都是新颖而独特的,无法提供训练 AI 模型所需的大量数据。
/ f G! [6 e" g0 M: X
3 w5 n& r0 C& M! i6 F% [$ G$ g, b* x
对此,Adam Gibson 呈现的解决方案是将模拟与 AI 结合起来,即在模拟器中创建许多 AI 可以学习的可能场景,这也是强化学习模型的训练方式。+ {5 S T8 D2 {
7 r3 @! _# W) R! o' [4 L
" p, W8 {2 O! r3 h, r& A4 v
强化学习不止与 Alpha Go 有关,同时也是我们通过模拟来做机器学习的一个分支。2 f; Q/ l. x! B0 l& C: j
7 `! \2 X+ a; e6 _
: _1 \( N8 U8 V5 }' T) V& _广告商如何投放广告才能实现效益最大化?物流公司如何优化送货路线才能降低成本?从供应链、智慧交通、人机协作再到工业流程模拟,工业 4.0 时代的许多问题其实都可以归结为 NP-Hard 问题,即组合优化问题,而强化学习为这些问题提供了一个可行的解决方案。利用强化学习学到的策略可以部署到各种设备中,以自适应的方式自动完成某些任务。" c, s$ n6 G, v1 _1 \
! j! A5 v6 n0 r! H
. ^! g7 ?5 O! w& ]0 S {% \3 m+ C + S0 M7 q0 o1 x' ] + S0 M7 q0 o1 x' ]
4 D: V. n1 i @9 x
! r" Y: w1 M0 N6 m 此外,Adam 强调,在这些场景中,我们要打造的是一个端到端的解决方案,建造一个中心化的系统,把数据收集到一起,然后不断进行模拟、迭代。2 v! L+ W6 i/ }- y" I1 k
# H/ l2 K: x: w9 u6 @4 m4 M
, Z: Q( g0 _- Q$ }; o
以上这些都是主单元的主题演讲的精彩内容。当日的主单元还包括WAIC黑客马拉松颁奖典礼、两个圆桌论坛等精彩环节。/ } n$ m* q. i0 }8 ~8 y
* J( U) p. n8 B3 e0 L, c
经过一天的高强度知识洗礼,相信大家都回味无穷,很多读者可能也都希望亲自听听大牛口中的「开发经验」都是什么样的。这里机器之心准备了重播链接,点击「阅读原文」观看整场 4 个多小时的知识盛宴。- ]9 E3 V! Y# V; H; ? b/ \# J3 @
) S9 F5 e' `7 u# j. U7 }5 }
! l8 `8 L t# {- a9 _6 B$ I8 l2 V+ \
% F5 j. Y; V) v3 ^本文为机器之心报道,转载请联系本公众号获得授权。$ t; }) R$ r* j4 Y/ \
✄------------------------------------------------加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com投稿或寻求报道:content@jiqizhixin.com广告 & 商务合作:bd@jiqizhixin.com
: `! \' F$ m; F7 p来源:http://mp.weixin.qq.com/s?src=11×tamp=1567326604&ver=1825&signature=e5agdBSSGq8YPKsP8BOGJpnGqq*vhv6ldkToM8IdpYozvvXc2EguqwjYOASEXKBiaECAQzjFhxZHiiHtZ30YFZnvnVHxzKCnZdPaPW15Cr1oNsjkbuc1SZkdZSDRxb6q&new=1
3 h9 D) o8 z, L5 K7 R" v% P7 |/ ?免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
 |手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图
|手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图

 发表于 2019-9-1 16:49:57
发表于 2019-9-1 16:49:57

